Microsoft's Azure Front Door Outage: How a Configuration Error Cascaded Into Global Service Disruption


October 29, 2025 - Just one week after AWS's DNS failure brought down thousands of services, Microsoft experienced a strikingly similar cascading failure. An inadvertent configuration change to Azure Front Door triggered a global outage affecting Azure, Microsoft 365, Xbox Live, and thousands of customer-facing services. The incident, tracked as MO1181369, disrupted services for millions of users worldwide and took over 12 hours to fully resolve.
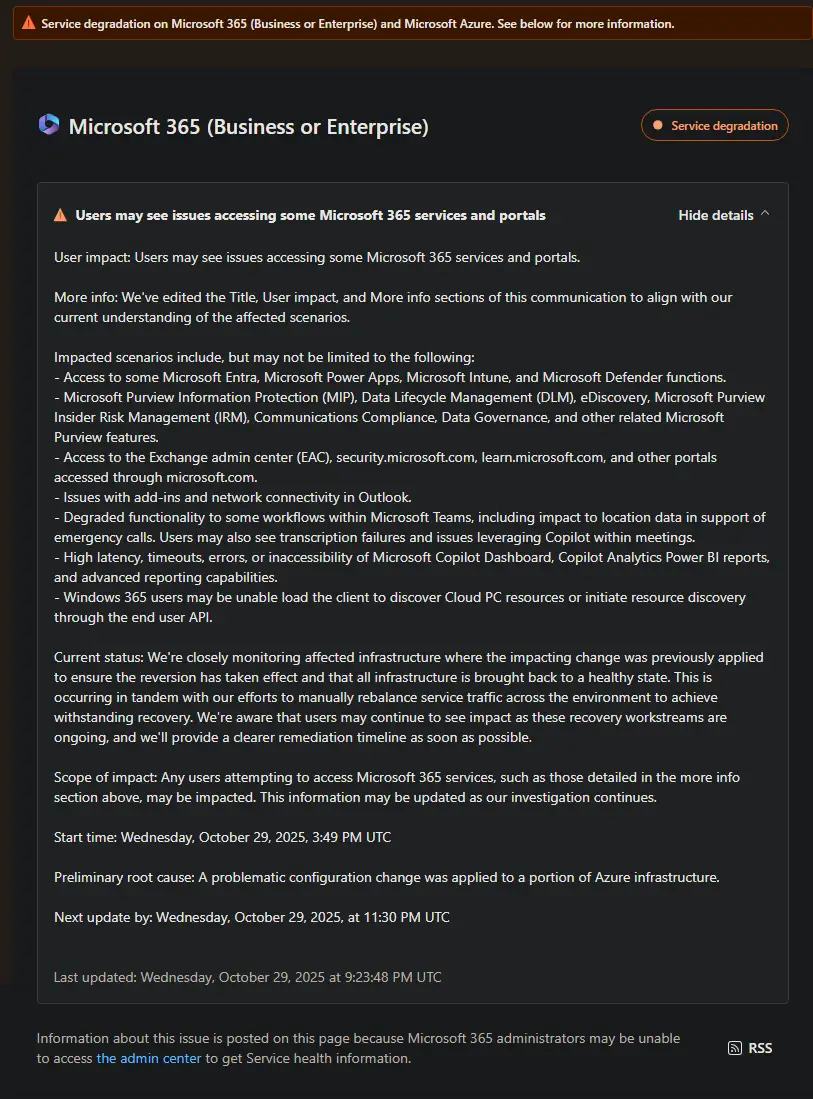
We’re investigating reports of issues accessing Microsoft 365 services and the Microsoft 365 admin center. More details can be found in the Service Health Dashboard under MO1181369.
— Microsoft 365 Status (@MSFT365Status) October 29, 2025
The back-to-back failures of two hyperscale cloud providers in a single week underscores a critical reality we explored in our AWS post-mortem: when foundational cloud infrastructure fails, the cascading effects ripple across the entire internet, affecting everything from healthcare systems to grocery stores, airlines to gaming platforms. This isn't just about Microsoft or AWS—it's about the concentrated risk embedded in our digital infrastructure.
The Incident Timeline
The outage began at approximately 16:00 UTC (12:00 PM ET) on October 29, 2025, when Microsoft's monitoring systems and external trackers detected elevated error rates, DNS anomalies, and widespread authentication failures. The timing was particularly unfortunate, occurring just hours before Microsoft's quarterly earnings release and during peak business hours across multiple time zones.
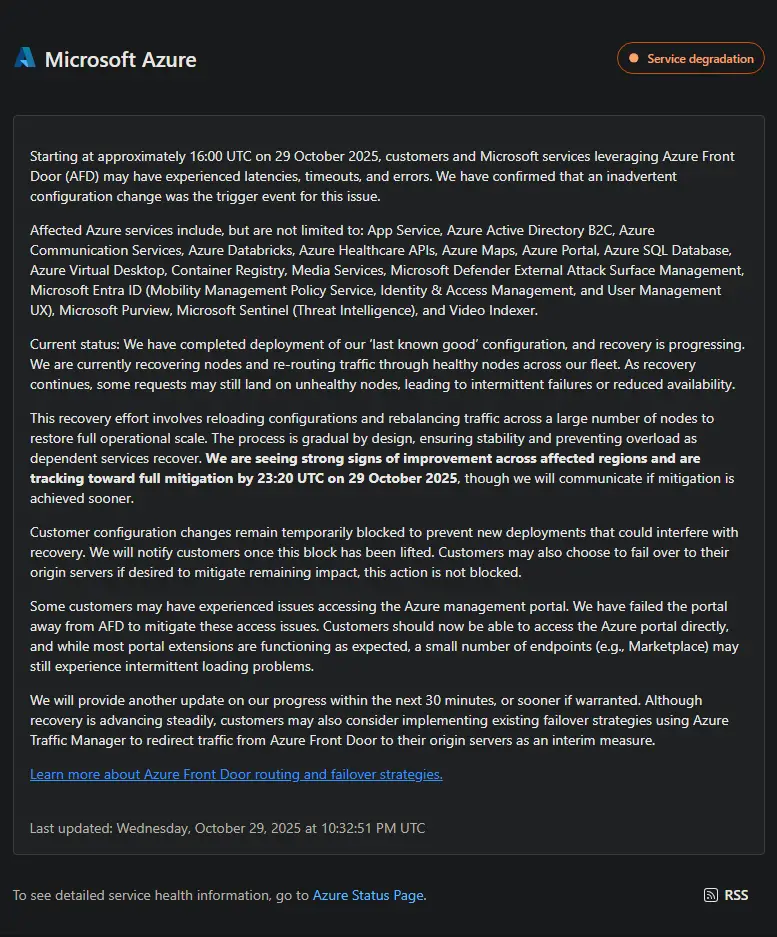



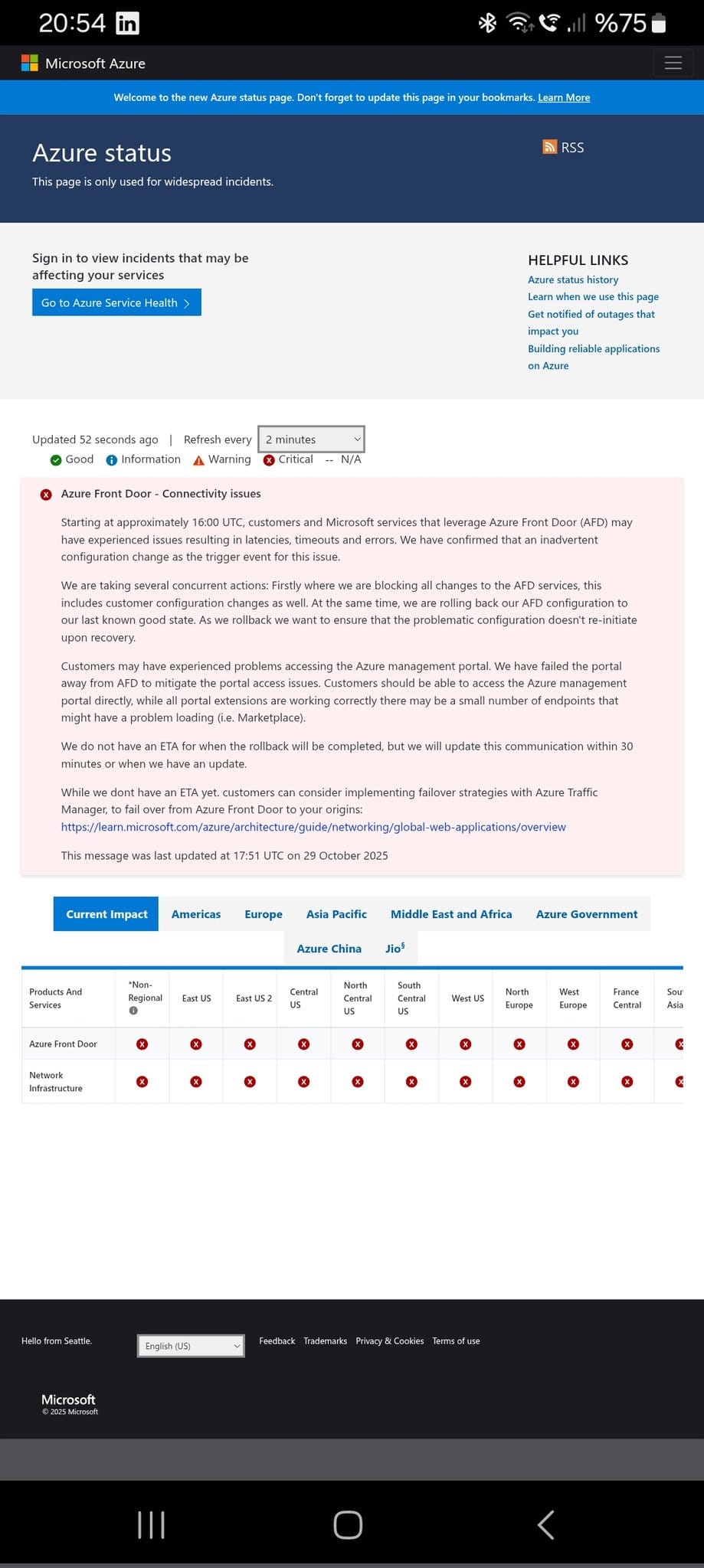
Microsoft's official Azure status page displayed a stark Critical severity indicator across all global regions—a rare designation reserved for the most severe incidents. The status update at 17:51 UTC stated:
"Starting at approximately 16:00 UTC, customers and Microsoft services that leverage Azure Front Door (AFD) may have experienced issues resulting in latencies, timeouts and errors. We have confirmed that an inadvertent configuration change was the trigger event for this issue."
Initial symptoms included:
- Failed sign-ins to Microsoft 365 services
- Blank or partially rendered Azure Portal blades
- 502/504 gateway errors across Microsoft services
- TLS handshake timeouts
- Xbox Live and Minecraft authentication failures
- DNS resolution failures preventing proper routing
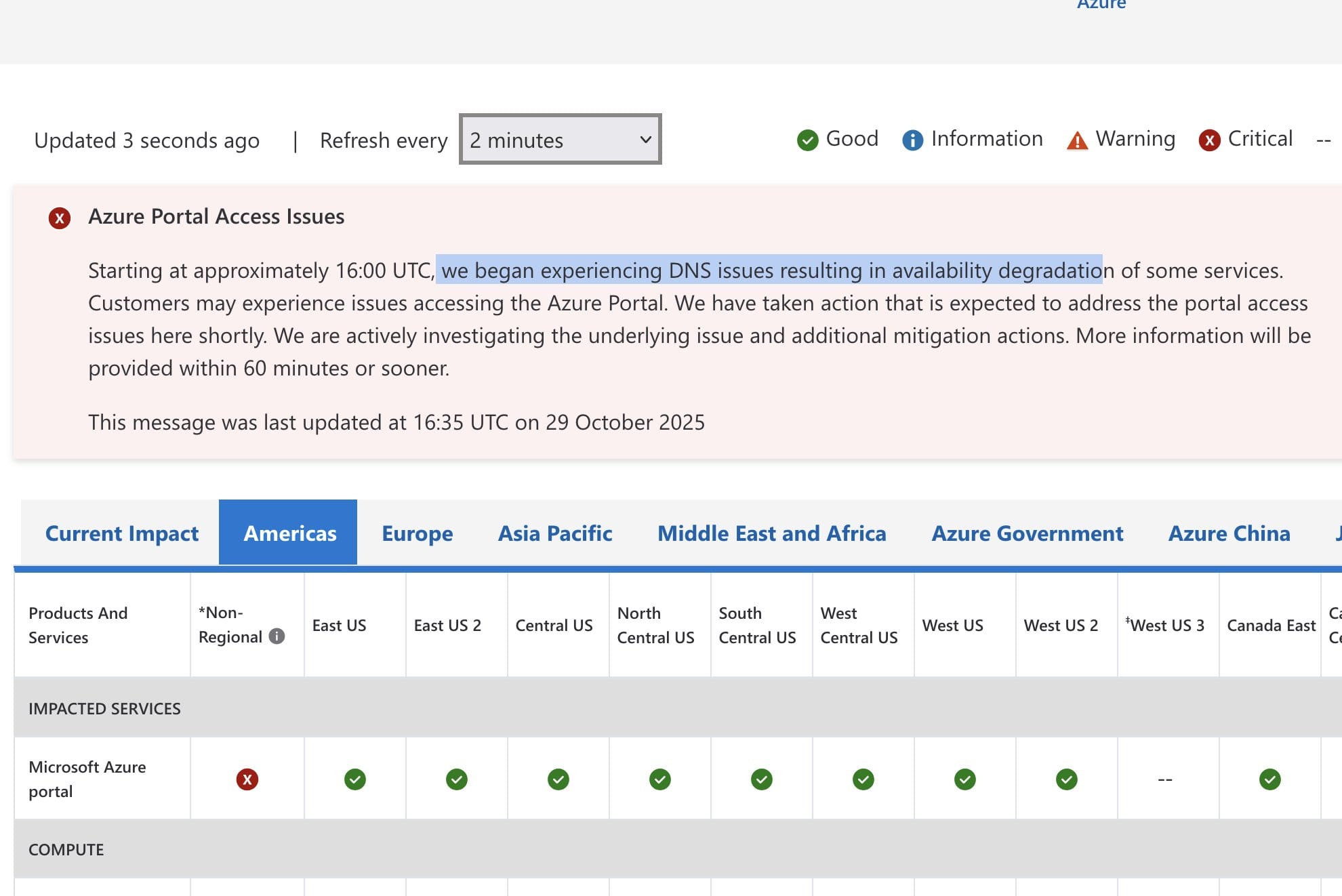
Real-time monitoring dashboards showed the incident's truly global nature—every Azure region worldwide was marked with critical status for both Azure Front Door and Network Infrastructure. No geographic area was spared.
At the incident's peak, outage tracking site Downdetector recorded over 16,600 user reports for Azure and approximately 9,000 reports for Microsoft 365. Some reports indicated peak counts exceeding 100,000 users across all Microsoft services combined. Microsoft's official status page showed critical failures across every global region—from Americas to Europe, Asia Pacific, Middle East and Africa, with both Azure Front Door and Network Infrastructure displaying red status indicators worldwide, leaving no region unaffected.
The actual impact was far broader than just Microsoft's own services. Real-time monitoring dashboards captured the cascading effect, showing simultaneous outage spikes across hundreds of dependent platforms—what can only be described as a "dependency avalanche." From enterprise collaboration tools like Zoom and Teams to gaming platforms like Halo Infinite and Sea of Thieves, from retail giants like Walmart and Costco to financial services providers, from educational platforms like Canvas by Instructure to healthcare systems like Heartland Payment Systems, the failure cascade painted a stark picture of how deeply Azure Front Door is embedded in global internet infrastructure. The outage affected thousands of third-party applications and websites that rely on Azure Front Door for edge routing and content delivery.
Root Cause: Azure Front Door Configuration Error
Microsoft identified the root cause as an inadvertent configuration change to Azure Front Door (AFD), the company's globally distributed Layer 7 edge and application delivery fabric. This wasn't a simple service outage or infrastructure failure—it was a control plane configuration error that propagated across Microsoft's global network of edge Points of Presence (PoPs).
The Azure status page painted a stark picture: every single geographic region displayed critical status—red indicators across Non-Regional, East US, East US 2, Central US, North Central US, South Central US, West US, West US 2, West US 3, Canada East, Canada Central, and extending to Europe, Asia Pacific, Middle East and Africa, Azure Government, and Azure China. Both "Azure Front Door" and "Network Infrastructure" showed simultaneous critical failures across the global map, indicating this was a truly worldwide control plane event, not a regional data center problem.
Azure Front Door serves as the critical "front door" for much of Microsoft's infrastructure, handling:
- TLS termination at edge locations
- Global HTTP/HTTPS routing and load balancing
- Web Application Firewall (WAF) enforcement
- DNS-level routing for endpoints
- CDN-style content caching
- Origin failover capabilities
Because AFD sits directly in front of critical Microsoft services—including Microsoft Entra ID (formerly Azure AD) for authentication and the Azure management plane—a configuration error at this layer had an immediate and devastating blast radius. When edge routing fails, even perfectly healthy backend services become unreachable.
The Cascading Impact
The outage affected an extensive range of Microsoft services and products:
Enterprise Services
According to Microsoft's Service Health Dashboard (MO1181369), the configuration change created widespread disruptions across the Microsoft 365 ecosystem:
- Microsoft 365 Admin Center: Administrators unable to access management portals or service health dashboards
- Exchange Online & Outlook: Email service disruptions, issues with add-ins and network connectivity
- Microsoft Teams: Connectivity and authentication issues, degraded functionality including location data problems for emergency calls, transcription failures, and Copilot integration issues within meetings
- SharePoint Online: Access problems and file synchronization delays
- Microsoft Intune: Device management and policy enforcement disruptions
- Microsoft Entra ID (formerly Azure AD): Authentication and identity services impaired, affecting single sign-on across the ecosystem
- Microsoft Power Platform: Power Apps, Power Automate experiencing access and execution issues
- Microsoft Defender: Security monitoring and threat intelligence functions affected
- Microsoft Purview: Comprehensive compliance disruption including:
- Information Protection (MIP) policies not applying
- Data Lifecycle Management (DLM) operations halted
- eDiscovery searches and holds unavailable
- Insider Risk Management (IRM) detection paused
- Communications Compliance monitoring interrupted
- Data Governance workflows suspended
- Microsoft Copilot: High latency, timeouts, and inaccessibility across Copilot Dashboard, Analytics Power BI reports, and advanced reporting capabilities
- Windows 365: Users unable to load Cloud PC resources or initiate resource discovery through the end user API
- Security and compliance portals: Issues accessing security.microsoft.com, learn.microsoft.com, and other admin portals accessed through microsoft.com domains
Cloud Infrastructure
- Azure Portal: Blank screens and failed resource loading
- Azure management APIs: Programmatic access disrupted
- Existing Azure-hosted applications: Widespread availability issues
Consumer Services
- Xbox Live: Sign-in failures preventing gaming
- Xbox Store and Game Pass: Storefront and download issues
- Minecraft: Authentication and multiplayer disruptions
- Microsoft Copilot: Service interruptions
- Outlook: Add-in and connectivity problems
Third-Party Impact: The Hidden Dependency Web
The outage extended far beyond Microsoft's own properties, revealing just how deeply Azure Front Door is embedded in critical business infrastructure. Real-time monitoring dashboards captured the cascading failures across sectors in vivid detail—showing simultaneous outage spikes for dozens of major platforms within minutes of each other. Each service displayed characteristic "heartbeat" graphs that suddenly flatlined or spiked with error rates, creating a visual representation of the dependency avalanche in real-time.
What the monitoring revealed was sobering: companies across entirely different sectors—from video game studios to healthcare providers, from financial institutions to educational platforms—all experiencing identical failure patterns at the same moment. This wasn't a series of independent incidents; it was a synchronized failure orchestrated by a single misconfigured edge service that sat invisibly in front of thousands of applications. The incident exposed what security professionals have long warned about: third-party dependencies create correlated failure modes that can take down entire business ecosystems simultaneously.
The scope of documented third-party failures included:
Retail and Commerce:
- Starbucks: Point-of-sale and ordering systems disrupted
- Costco and Kroger: Retail operations and payment processing impacted
- Walmart.com: E-commerce platform experiencing connectivity issues
- Chipotle: Online ordering systems affected
Financial Services:
- Capital One: Banking services experiencing intermittent failures
- mrcooper: Mortgage servicing platform disrupted
- Heartland Payment Systems: Payment processing delays
Education and Healthcare:
- Canvas by Instructure: Learning management systems offline during peak class hours
- Blackbaud: Nonprofit and education software disrupted
- MyChart (Epic Systems): Patient portal access failures
- Wolters Kluwer: Healthcare and legal information systems affected
Transportation and Logistics:
- Alaska Airlines: Disruptions to key systems including website and check-in
- Dutch railway system: Travel planning platforms offline
- Hotschedules: Restaurant and hospitality scheduling systems down
Technology and Gaming:
- Zoom: Video conferencing experiencing authentication issues
- Visual Studio Team Services: Developer tools and CI/CD pipelines disrupted
- Halo Infinite, Sea of Thieves, Helldivers 2: Game authentication and multiplayer failures
- Rackspace Technology: Managed cloud services impacted
Telecommunications and ISPs:
- Xfinity (Comcast): Customer portal and service management affected
- Astound Broadband: ISP management systems disrupted
Enterprise Software:
- ArcGIS (Esri): Geospatial and mapping services offline
- BandLab: Audio production platform experiencing issues
- GoTo: Remote access and collaboration tools affected
- Groupme: Messaging platform disrupted
- Sophos: Security management consoles inaccessible
- Cloudflare: Some edge services showing degradation
- Raptor Technologies: School safety and visitor management systems offline
Education Management:
- FACTS: School information and tuition management systems down
- Renweb: Student information systems affected
Even Microsoft's own status pages—including status.cloud.microsoft—went intermittently offline during the early stages, leaving customers unable to monitor recovery progress. This created an additional communication challenge as users couldn't access official incident information.
The breadth of this impact demonstrates what we explored in our analysis of the AWS outage: modern business operations have become a complex web of dependencies where a single infrastructure failure can cascade across entirely unrelated sectors. A configuration error in Azure's edge routing didn't just affect Microsoft—it disrupted healthcare appointments, prevented students from accessing coursework, stopped financial transactions, and grounded airline operations.
Microsoft's Response and Remediation
Microsoft's engineering teams moved quickly to contain and resolve the incident, following a textbook disaster recovery playbook. The company provided regular status updates via its Azure Status page (status.cloud.microsoft) and @MSFT365Status Twitter account.
However, in a troubling irony that underscored the severity of the incident, both of these communication channels experienced intermittent availability issues during the early stages of the outage. The status.cloud.microsoft page itself went offline multiple times, forcing Microsoft to acknowledge via Twitter: "Many users are reporting that status.cloud.microsoft is intermittently unavailable. While we work to address that problem, we'll provide frequent updates to @MSFT365Status to ensure the affected users remain informed."
For customers trying to access incident MO1181369 in the Microsoft 365 admin center, Microsoft had to provide alternative instructions: "For users that are unable to access the MO1181369 in the admin center, please visit status.cloud.microsoft to view updates on this event"—advice that proved difficult to follow when that very status page was also experiencing outages. This created a communication crisis layered on top of the technical crisis, leaving many administrators blind to recovery progress at the precise moment they needed visibility most.
Immediate Actions (First 2 Hours)
16:00 UTC - Incident Detection
Microsoft detected "DNS issues resulting in availability degradation of some services" affecting Azure Portal access.
16:35 UTC - Initial Public Communication
Azure status page updated with Critical severity across all regions. Microsoft confirmed customers experiencing issues accessing the Azure Portal and began actively investigating the underlying issue.
17:51 UTC - Root Cause Identified
Microsoft confirmed: "An inadvertent configuration change was the trigger event for this issue." The company announced it was:
- Configuration freeze: All changes to Azure Front Door were immediately blocked to prevent further propagation of the faulty configuration
- Traffic rerouting: Affected traffic was being redirected to alternate healthy infrastructure
- Concurrent actions: Teams were "blocking all changes to the AFD services" and "rolling back AFD configuration to our last known good state"
Microsoft also took the unusual step of failing the Azure Portal away from AFD to restore management access, acknowledging that administrators needed alternative paths when the primary management console was impaired.
Recovery Phase (Hours 2-8)
18:XX UTC - Rollback Initiated
Microsoft announced: "We have initiated the deployment of our 'last known good' configuration. This is expected to be fully deployed in about 30 minutes from which point customers will start to see initial signs of recovery."
The company warned that customer configuration changes would remain blocked during the recovery process—a necessary precaution to prevent introducing new complications while restoring baseline service.
19:XX UTC - Progressive Node Recovery
Status updates indicated Microsoft was:
- Configuration rollback: Deploying the previous healthy configuration to affected infrastructure
- Node recovery: Restarting and recovering edge nodes systematically
- Traffic rebalancing: Manual rebalancing of service traffic across healthy Points of Presence
- Extended monitoring: "Closely monitoring the environment to ensure the reversion has taken effect and that all infrastructure returns to a healthy state"
Microsoft's technical teams emphasized they were working to "manually rebalance service traffic across the environment to achieve withstanding recovery"—indicating the extent of manual intervention required.
Stabilization Phase (Hours 8-14)
22:XX UTC - Service Health Improving
Microsoft reported: "The AFD service is now operating above 98% availability. While the majority of customers and services are mitigated or seeing strong improvement across affected regions, we are continuing to work on tail-end recovery for remaining impacted customers and services."
The company revised its mitigation timeline, initially targeting full recovery by 23:20 UTC but later extending to 00:40 UTC on October 30 as residual issues persisted.
October 30, Early Morning - Full Resolution
After extended monitoring, Microsoft confirmed: "After extended monitoring, we confirmed that impact stemming from the Azure configuration change has been resolved."
However, the company acknowledged a discrepancy between technical metrics and user experience: "We've confirmed that service health has largely recovered; however, user reports of impact haven't yet returned to pre-incident thresholds." This statement highlighted how DNS caching, session state, and client-side factors can prolong perceived impact even after infrastructure is technically restored.
Microsoft reported that AFD service availability climbed above 98% within hours of beginning remediation, though residual effects persisted for some users as DNS caches and routing tables converged globally. Full resolution was confirmed approximately 14 hours after the initial incident, though some customers experienced intermittent issues beyond that point.
Broader Context: The October 2025 Cloud Reliability Crisis
This incident occurred just one week after Amazon Web Services (AWS) suffered a major DNS-related outage in its US-EAST-1 region, which also disrupted thousands of services including Signal, Snapchat, and Reddit. The back-to-back failures of two major cloud providers within seven days represents more than coincidence—it exposes systemic vulnerabilities in how we've architected the modern internet.
The Pattern of Cascading Failures
As we detailed in our analysis of the AWS outage and third-party dependencies, both incidents share disturbing similarities:
Identical Root Causes:
- AWS: DNS configuration error in US-EAST-1 affecting Route 53 and dependent services
- Microsoft: DNS and routing configuration error in Azure Front Door affecting global edge infrastructure
Similar Cascading Patterns:
- Edge/DNS layer failures preventing access to otherwise healthy backend services
- Identity and authentication systems becoming inaccessible
- Management consoles going offline precisely when administrators needed them most
- Cache and DNS propagation extending recovery time beyond the configuration fixes
Comparable Business Impact:
- Thousands of dependent services affected simultaneously
- Cross-sector disruption (retail, healthcare, education, finance, transportation)
- Estimated economic impact in the hundreds of millions of dollars per hour
The AWS outage taught us that third-party dependencies create single points of failure. The Microsoft outage, occurring just days later, reinforced that lesson and added a troubling corollary: even the most sophisticated cloud providers are vulnerable to the same classes of configuration errors.
Market Concentration Amplifies Risk
Market concentration plays a critical role in amplifying these incidents. AWS, Microsoft Azure, and Google Cloud collectively control approximately 63% of the cloud infrastructure market, with AWS holding roughly 30% and Microsoft approximately 20%. When one of these platforms experiences a control plane failure, the ripple effects extend across vast portions of the internet.
This concentration creates what economists call "systemic risk"—when individual institutional failures threaten the stability of the entire system. We're now seeing this play out in cloud infrastructure:
- Week of October 20: AWS DNS failure disrupts thousands of services
- Week of October 29: Microsoft AFD failure disrupts thousands of services
- Combined impact: Millions of users, billions in economic losses, critical infrastructure at risk
Cybersecurity expert Mehdi Daoudi, CEO of Catchpoint, emphasized the systemic risk: "The Azure outage underscores the vulnerability of the internet's core infrastructure—even among hyperscale providers. Resilience gaps are still widespread across even the most advanced infrastructures."
October 2025: A Month of Cloud Failures
Microsoft's October 29 outage was actually the third Azure incident in October 2025 alone:
- October 9: Azure Front Door issues in Africa, Europe, Asia Pacific, and Middle East
- October 9: Azure Portal outage affecting ~45% of customers
- October 29: This global AFD configuration error
Combined with the AWS outage on October 20 and various smaller incidents across other providers, October 2025 may be remembered as a watershed moment that forced enterprises and regulators to confront uncomfortable questions:
- Is cloud concentration creating too much systemic risk?
- Should critical infrastructure have regulatory requirements for multi-cloud resilience?
- Are current SLAs adequate given the cascading impact of these failures?
- Do enterprises have sufficient visibility into their dependency chains?
This pattern has intensified scrutiny from:
- Enterprise customers evaluating vendor commitments and contractual terms
- Regulatory bodies examining critical infrastructure dependencies
- Board-level executives questioning cloud concentration risk
- Risk management teams reassessing business continuity strategies
- Insurance carriers repricing cyber and business interruption policies
Technical Deep Dive: Why Configuration Errors Are So Dangerous
Modern cloud platforms operate at a scale where automation is essential, but that automation also creates new classes of risk. Here's why this particular type of failure is so impactful:
Control Plane vs. Data Plane Failures
- Data plane failures (hardware failures, network issues at specific locations) typically affect only traffic passing through the failed component and can be quickly rerouted
- Control plane failures (configuration errors, routing table corruption) can instantaneously affect global behavior across all edge locations
The October 29 incident was a control plane amplification event—a single misconfiguration propagated to routing rules, DNS mappings, or TLS termination behavior across Microsoft's global edge fabric simultaneously.
The Identity Dependency Problem
Because Microsoft uses Azure Front Door to front its identity services (Microsoft Entra ID), a failure at the edge layer doesn't just prevent access to applications—it prevents authentication entirely. This creates a scenario where:
- User attempts to sign in to any Microsoft service
- Request hits AFD with faulty routing configuration
- AFD cannot properly route to Entra ID backend
- Authentication fails before reaching identity systems
- User sees authentication failure even though Entra ID is healthy
This dependency chain means that edge failures can masquerade as much broader service failures, making initial diagnosis more complex.
DNS and Cache Propagation
Even after Microsoft rolled back the faulty configuration, recovery was prolonged by:
- DNS TTL values: Cached DNS records at ISPs and recursive resolvers
- Browser caches: Client-side cached routing information
- CDN edge caches: Stale routing state at edge locations
- Session state: Existing sessions requiring re-establishment
These factors mean that control plane fixes don't result in instant recovery—there's always a "tail" of residual impact as various caching layers converge to the new (corrected) state.
Lessons for Enterprise Security and IT Teams
This incident provides several critical lessons for organizations that depend on cloud infrastructure:
1. Understand Your Edge Dependencies
Many organizations don't fully understand their dependency on cloud edge services. If you use:
- Azure Front Door for application delivery
- Microsoft Entra ID as your primary identity provider
- Azure Portal as your primary management interface
...then you have a single point of failure that can render all of these systems inaccessible simultaneously. Catalog these dependencies and understand their blast radius.
2. Implement Multi-Path Resilience
- Out-of-band management: Maintain alternative management paths (PowerShell, CLI, dedicated management networks) that don't rely on the same edge infrastructure
- Break-glass accounts: Establish emergency access procedures with alternative authentication paths
- Multi-cloud or hybrid approaches: Consider architectures that can fail over between providers
- Local admin tooling: Keep local administrative capabilities for critical systems
3. Improve Change Control Visibility
Enterprise customers should demand:
- Advance notification of significant configuration changes
- Staged rollouts with canary deployments for control plane changes
- Faster rollback capabilities built into provider SLAs
- Transparent post-incident reports with root cause analysis and remediation commitments
4. Test Your Disaster Recovery Plans
This incident revealed gaps in many organizations' DR plans:
- Can your administrators manage infrastructure when the Azure Portal is down?
- Do you have documented runbooks for "provider outage" scenarios?
- Have you tested your communication plans when status pages are also offline?
- Do you have alternative observability tools that don't depend on the affected provider?
5. Implement Comprehensive Monitoring
Don't rely solely on provider health dashboards:
- Deploy synthetic monitoring from multiple vantage points
- Monitor authentication flows end-to-end
- Track TLS handshake success rates at the edge
- Alert on elevated latency or error rates before full outages occur
The October 2025 Cloud Reliability Crisis
Microsoft's October 29 outage was the third Azure incident in October 2025 alone:
- October 9: Azure Front Door issues in Africa, Europe, Asia Pacific, and Middle East
- October 9: Azure Portal outage affecting ~45% of customers
- October 29: This global AFD configuration error
Combined with the AWS outage on October 20, this represents a troubling pattern that has intensified scrutiny from:
- Enterprise customers evaluating vendor commitments and contractual terms
- Regulatory bodies examining critical infrastructure dependencies
- Board-level executives questioning cloud concentration risk
- Risk management teams reassessing business continuity strategies
Redefining Critical Infrastructure in the Cloud Era
The October 2025 cloud failures—AWS and Microsoft in rapid succession—force us to confront an uncomfortable reality we explored in our AWS post-mortem: cloud infrastructure providers have become de facto critical infrastructure, yet they operate without the regulatory oversight, redundancy requirements, or transparency expectations we demand from traditional utilities.
What Traditional Critical Infrastructure Looks Like
When we think of critical infrastructure, we typically envision:
- Power grids with redundant generation, multiple transmission paths, and strict regulatory oversight
- Water systems with backup sources, storage capacity, and emergency response protocols
- Transportation networks with alternative routes, backup systems, and disaster recovery plans
- Financial systems with circuit breakers, backup clearing houses, and regulatory supervision
These systems are recognized as essential to national security and economic stability. They're subject to:
- Mandatory redundancy and resilience requirements
- Regular stress testing and disaster recovery drills
- Regulatory oversight and compliance audits
- Incident reporting and transparency obligations
- Strategic national planning and investment
What Cloud Infrastructure Actually Looks Like
Now compare that to cloud infrastructure providers:
- Voluntary SLAs with no legal enforcement mechanism for most customers
- Self-regulated change management with limited external oversight
- Opaque operations where configuration errors can propagate globally before detection
- Concentration risk with three providers controlling 63% of the market
- Limited transparency about incident root causes, often released weeks or months later
- No mandatory redundancy requirements for edge routing or identity services
The Azure Front Door outage demonstrates the problem: a single configuration change affected:
- Healthcare systems managing patient care
- Financial services processing transactions
- Airlines managing flight operations
- Schools delivering education
- Retailers processing sales
- Government services managing citizen access
This is the definition of critical infrastructure—yet it operates more like a private utility with limited accountability.
The Dependency Chain Nobody Maps
Both the AWS and Microsoft outages revealed something troubling: most organizations don't fully understand their dependency chains. When Azure Front Door failed, it didn't just affect organizations that explicitly chose to use AFD—it affected:
- Organizations using Microsoft 365 (who depend on Entra ID, which depends on AFD)
- Organizations using Azure Portal (which depends on AFD for management access)
- Organizations whose vendors use Azure (dependency chain invisible to the end customer)
- Organizations whose authentication flows route through Microsoft services
- Organizations using third-party services that depend on any of the above
This creates what we called in the AWS analysis "dependency chain opacity"—you can't secure or plan around risks you don't know exist.
The Questions We Must Answer
The October 2025 cloud crisis demands answers to hard questions:
For Regulators:
- Should cloud providers be classified as critical infrastructure utilities?
- Do we need mandatory resilience standards for edge routing and identity services?
- Should there be regulatory approval required for control plane configuration changes?
- Do we need strategic national cloud infrastructure to reduce dependence on commercial providers?
For Cloud Providers:
- What level of transparency and advance notice should customers receive for significant changes?
- Should there be industry-wide standards for change management and canary deployments?
- How can providers reduce single points of failure in edge routing and identity layers?
- What contractual commitments should be made around incident resolution and communication?
For Enterprises:
- How do you maintain operations when your cloud provider's management console is offline?
- What level of multi-cloud investment is justified to mitigate concentration risk?
- How do you map and monitor dependency chains that extend through multiple providers?
- When do cloud dependencies become unacceptable single points of failure?
For Society:
- At what point does cloud concentration become a national security issue?
- Should there be limits on how much critical infrastructure can depend on a single provider?
- Who bears liability when a configuration error cascades into billions in economic losses?
- How do we balance innovation and efficiency with resilience and redundancy?
The Bottom Line
Microsoft's response to the incident demonstrated mature operational capabilities—rapid detection, appropriate containment measures, and progressive recovery. The company's transparency in acknowledging the "inadvertent configuration change" and providing regular status updates was commendable compared to many technology companies' crisis communication.
However, operational competence doesn't address the structural problem. The incident exposes a fundamental tension we've now seen play out twice in one month: the same centralization that enables global scale and efficiency also creates single points of failure with catastrophic blast radius.
The Real Lesson: It's Not About Microsoft or AWS
The October 2025 cloud crisis isn't really about Microsoft's configuration error or AWS's DNS failure. It's about a structural vulnerability in how we've built the modern internet:
We've created critical infrastructure without critical infrastructure protections.
As we wrote in our analysis of the AWS outage, we've allowed essential services—healthcare, finance, education, transportation, government—to become dependent on a handful of commercial providers operating without the redundancy, oversight, or accountability we demand from traditional critical infrastructure.
The pattern is now undeniable:
- Week 1: AWS DNS configuration error takes down thousands of services
- Week 2: Microsoft AFD configuration error takes down thousands of services
- Conclusion: This isn't bad luck—it's a systemic vulnerability
What Needs to Change
For cybersecurity professionals, IT leaders, and risk managers, this double-punch of cloud failures demands action:
Immediate (This Quarter):
- Map your complete dependency chains, including third-party vendors
- Document emergency procedures for "provider portal down" scenarios
- Test your ability to manage infrastructure via CLI/API when web consoles fail
- Implement independent monitoring that doesn't rely on provider infrastructure
- Review and strengthen your incident communication plans
Medium-Term (This Year):
- Evaluate multi-cloud architectures for truly critical workloads
- Implement DNS-level and edge-level redundancy across providers
- Negotiate SLAs that include change management visibility and faster resolution commitments
- Build organizational competencies in hybrid and multi-cloud operations
- Develop break-glass procedures with alternative authentication paths
Strategic (Ongoing):
- Participate in industry conversations about cloud resilience standards
- Push for regulatory frameworks that treat cloud infrastructure as critical infrastructure
- Support transparency initiatives that give enterprises visibility into provider dependencies
- Consider whether certain workloads should remain on-premises or in private infrastructure
- Advocate for competitive cloud ecosystems that reduce concentration risk
The Cost of Inaction
The cost of implementing these safeguards must be weighed against the business impact of similar outages—which for many organizations can range from hundreds of thousands to millions of dollars per hour of downtime. But there's a deeper cost that's harder to quantify:
Loss of trust in digital infrastructure.
When hospitals can't access patient records, when airlines can't board passengers, when banks can't process transactions, when schools can't deliver lessons—all because of a configuration error at a cloud provider—we're forced to confront the fragility of systems we've come to see as invincible.
Looking Forward
October 2025 may be remembered as the month that forced a reckoning with cloud concentration risk. Two major providers, two configuration errors, two global outages—all within days of each other. The parallels are too stark to ignore, and the pattern is too dangerous to accept as the new normal.
As we concluded in our AWS analysis: When the cloud falls, everything falls with it. The question isn't whether it will happen again—it's whether we'll be ready when it does.
For enterprises: Start treating cloud dependencies like the critical infrastructure they are. Map them, monitor them, redundancy them, and have a plan for when they fail.
For providers: Recognize that you're no longer just offering computing services—you're operating critical infrastructure that society depends on. Accept the transparency, oversight, and redundancy obligations that come with that role.
For regulators: The October 2025 failures should be a wake-up call. Cloud infrastructure concentration has become a systemic risk that demands a systemic response.
The cloud revolutionized computing, but we built it without the safety rails we put around other critical infrastructure. October 2025 showed us what happens when those rails are missing. Now we need to decide: Do we accept this level of fragility as the price of innovation, or do we demand better?
Related Reading
This article is part of our October 2025 Cloud Crisis series:
📖 When the Cloud Falls: Third-Party Dependencies and the New Definition of Critical Infrastructure
Our in-depth analysis of the AWS DNS outage that preceded this Microsoft failure by just one week. Understanding both incidents together reveals the systemic vulnerabilities in cloud infrastructure concentration.
Key themes across both analyses:
- How configuration errors in edge/DNS layers cascade across thousands of dependent services
- Why market concentration (AWS + Azure + Google = 63% of cloud market) amplifies systemic risk
- The dependency chain opacity problem: most organizations don't know what they depend on
- Why cloud providers should be regulated as critical infrastructure
- Practical steps enterprises can take to reduce concentration risk
Reading both articles provides the complete picture of October 2025's back-to-back cloud failures and what they mean for the future of internet infrastructure.
Technical Recommendations
For organizations using Azure and Microsoft 365, consider implementing these technical mitigations:
Immediate Actions:
- Document emergency access procedures that don't rely on Azure Portal
- Enable and test PowerShell/CLI access to Azure resources
- Establish break-glass admin accounts with alternative MFA methods
- Create runbooks for "portal down" scenarios
Medium-Term Investments:
- Implement Azure Traffic Manager for DNS-level failover
- Deploy multi-region architectures with automatic failover
- Set up synthetic monitoring from external vantage points
- Consider hybrid identity solutions that don't exclusively depend on Entra ID
Long-Term Strategic Planning:
- Evaluate multi-cloud architectures for critical workloads
- Negotiate SLAs that include change management visibility
- Implement robust observability with provider-independent tooling
- Develop organizational competencies in hybrid and multi-cloud operations
The cost of these investments must be weighed against the business impact of similar outages—which for many organizations can range from hundreds of thousands to millions of dollars per hour of downtime.
This analysis is based on public information from Microsoft's incident reports, status updates, and independent monitoring data. Organizations should consult Microsoft's detailed post-incident review when it becomes available for authoritative technical details and long-term remediation commitments.