When Cloudflare Sneezes, Half the Internet Catches a Cold: The November 2025 Outage and the Critical Need for Third-Party Risk Management

Executive Summary
On the morning of November 18, 2025, a configuration error at Cloudflare triggered a cascading failure that rendered significant portions of the internet inaccessible for several hours. ChatGPT, X (formerly Twitter), Spotify, League of Legends, and countless other services went dark, exposing an uncomfortable truth: our modern digital infrastructure is precariously balanced on a handful of critical service providers. This incident marks the THIRD major infrastructure failure in less than one month—following AWS's devastating outage on October 20, 2025 and Microsoft's Azure Front Door failure on October 29, 2025. This represents a pattern that cybersecurity and risk management professionals can no longer ignore.
The Incident: A Configuration File Gone Rogue
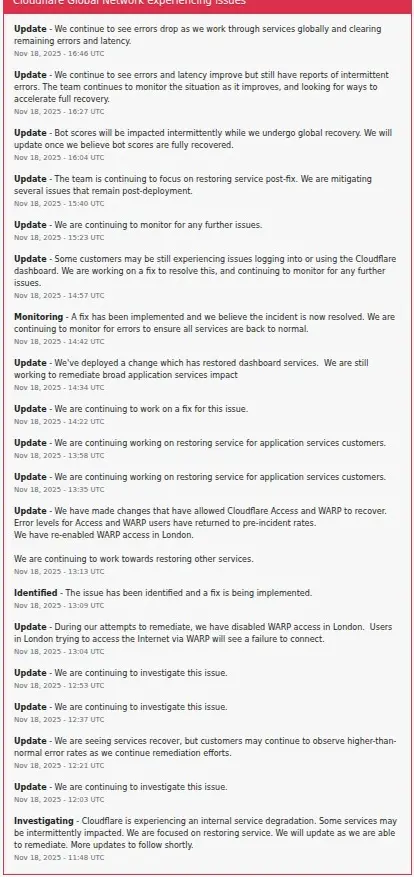
Timeline of Events
- 11:20 UTC (6:20 AM ET): Cloudflare observes a "spike in unusual traffic" to one of its services
- 12:03 UTC (7:03 AM ET): Cloudflare confirms it is "continuing to investigate" the issue via its status page
- 13:09 UTC (8:09 AM ET): The company announces the root cause has been identified and a fix is being implemented
- 14:30 UTC (9:30 AM ET): Services begin recovering, though sporadic issues continue
- 14:42 UTC (9:42 AM ET): Cloudflare declares the incident resolved, though monitoring continues
Root Cause: A Latent Bug Triggered by Routine Configuration Change
According to Cloudflare's official statements, what initially appeared as an "unusual traffic spike" turned out to be a latent bug in their bot mitigation service that was triggered by a routine configuration change. Cloudflare CTO John Graham-Cumming issued a direct apology:
"I won't mince words: earlier today we failed our customers and the broader Internet when a problem in Cloudflare network impacted large amounts of traffic that rely on us. In short, a latent bug in a service underpinning our bot mitigation capability started to crash after a routine configuration change we made. That cascaded into a broad degradation to our network and other services. This was not an attack. That issue, impact it caused, and time to resolution is unacceptable."
The technical details reveal a more complex failure than initially thought: An automatically generated configuration file used to manage threat traffic grew beyond its expected size of entries. This oversized configuration triggered a latent bug in the bot mitigation service, causing it to crash. The crashes then cascaded into broader network degradation affecting multiple Cloudflare services. Initially, Cloudflare reported seeing "a spike in unusual traffic to one of Cloudflare's services beginning at 11:20 UTC," which caused speculation about a potential DDoS attack (given Cloudflare had just blocked a record-setting 11.5 Tbps DDoS attack two months earlier). However, the company quickly clarified: "This was not an attack." The "unusual traffic" was actually the symptom, not the cause—the cascading crashes generated abnormal traffic patterns as services tried to recover and reroute. Cloudflare's status page tracked the incident in real-time, with updates posted throughout the recovery process.
https://x.com/dok2001/status/1990791419653484646?s=20
The DNS and Legacy Network Problem
Security experts point to deeper systemic issues. Jake Moore, global cybersecurity advisor at ESET, noted that these outages are occurring due to Domain Name System (DNS) problems with systems that are "most likely overwhelmed." The technology is based on "an outdated, legacy network" that redirects words in web addresses into computer-friendly numbers. "When this system fails, it catastrophically collapses and causes these outages." Rob Demain, CEO at e2e-assure, warned that recovery could take significant time: "What is likely an enormous global traffic backlog will be building, so we could be waiting a while for things to fully recover. This is a reminder of how fragile our digital systems can be and how much we rely on just a few key players to keep the internet running smoothly."
Security Implications Beyond Availability
Graeme Stewart, head of public sector at Check Point Software, highlighted the cybersecurity dimensions: "When a platform of this size slips, the impact spreads far and fast, and everyone feels it at once. Any platform that carries this much of the world's traffic becomes a target. Even an accidental outage creates noise and uncertainty that attackers know how to use. If an incident of this scale were deliberately triggered, the disruption would spread across countries that use these platforms to communicate with the public and deliver essential services." This scenario is particularly concerning given Cloudflare's previous incident on November 14, 2024, when a blank configuration being pushed to their Logfwdr system resulted in 55% of customer logs being lost over a 3.5-hour period. That incident also involved cascading failures triggered by configuration errors and insufficient safeguards for edge cases. The recurrence of configuration-related failures within such a short timeframe raises serious questions about Cloudflare's change management processes and the fundamental architecture of systems managing such critical internet infrastructure. Graham-Cumming acknowledged the severity: "The trust our customers place in us is what we value the most and we are going to do what it takes to earn that back. Transparency about what happened matters, and we plan to share a breakdown with more details in a few hours."
"Given the importance of Cloudflare's services, any outage is unacceptable. We apologize to our customers and the Internet in general for letting you down today."
— — Cloudflare Spokesperson, November 18, 2025
Blast Radius: Who Went Dark and Why It Matters
The November 18 outage demonstrated Cloudflare's reach across the modern internet. Major affected services included:
- AI and Communication Platforms: OpenAI's ChatGPT and Sora, Anthropic's Claude, X (Twitter), Truth Social, Zoom
- Entertainment and Media: Spotify, League of Legends, Valorant, RuneScape, Archive of Our Own, Letterboxd
- E-commerce and Business Services: Shopify, Canva, Indeed, DoorDash, Uber Eats, UPS, Varo, Dayforce, McDonald's self-service kiosks
- Infrastructure and Utilities: NJ Transit digital services, PADS (Personnel Access Data System) for nuclear plant background checks, daycare check-in apps
- Development and Monitoring Tools: DownDetector itself (ironically unable to report on the Cloudflare outage initially), Printables and Thangs (3D printing model repositories), tech news sites including The Register, Notebookcheck, and Videocardz
- Security and Networking: Windscribe VPN status pages
The breadth of impact was stunning in its diversity. McDonald's customers couldn't use self-service kiosks. Nuclear power plant visitors couldn't be checked in through PADS background check systems (though plant operations themselves were unaffected). Daycare centers reverted to pen-and-paper check-ins as their tablet apps failed. RuneScape players couldn't access the game or its wiki. 3D printing enthusiasts couldn't download models. Even tech news sites covering the outage were themselves taken offline. Perhaps most revealing was the discovery that users couldn't even research how widespread Cloudflare's usage is—because the search results explaining Cloudflare's market penetration were themselves hosted behind Cloudflare. This circular dependency illustrates the profound centralization of internet infrastructure.
Real-World Consequences: From Daycare to Nuclear Plants
The outage's impact extended far beyond inconvenience, affecting critical daily operations across sectors:
- Childcare Operations: Daycare centers that rely on tablet-based check-in/check-out apps had to revert to manual pen-and-paper processes, creating operational challenges during busy drop-off and pickup times
- Nuclear Security: PADS (Personnel Access Data System), used for background checks and access authorization at U.S. commercial nuclear facilities, was unavailable. While this didn't affect plant operations or safety, it prevented visitor access and worker authorization verification
- Quick-Service Restaurants: McDonald's self-service kiosks displayed error messages, forcing locations to rely solely on counter service during peak hours
- Gaming Communities: Riot Games reported players being disconnected from League of Legends and Valorant mid-game, while RuneScape players lost access to both the game and its community wiki
- Remote Work: Tools like Canva became inaccessible, halting design and content creation work for countless businesses and individuals
The 20% Problem and a $60 Billion Price Tag
Cloudflare's software manages and secures traffic for approximately 19-20% of the web, including roughly 35% of Fortune 500 companies. When a company protecting one-fifth of the internet experiences a configuration error, the ripple effects are immediate and global. According to website maintenance service SupportMy.website, the outage cost an estimated $5 billion to $15 billion per hour. With the outage lasting approximately four hours from initial reports to substantial recovery, the total economic impact could reach $60 billion. As Jason Long, founder of SupportMy.website noted: "From reputation to the bottom line, Cloudflare is one of those systems that businesses don't realize they need or even use sometimes. But when it's down, they feel it." Businesses lost revenue, users lost productivity, and critical services became inaccessible—all because of a configuration file that grew too large.
A Troubling Pattern: Three Major Failures in One Month
The Cloudflare outage doesn't exist in isolation. The past month has witnessed an alarming concentration of major infrastructure failures that should terrify every security professional:
October 20, 2025: The AWS Catastrophe
As we detailed in our analysis "When the Cloud Falls: Third-Party Dependencies and the New Definition of Critical Infrastructure," Amazon Web Services experienced one of the largest internet outages in history when a DNS resolution failure in US-EAST-1 took down over 1,000 services. Downdetector logged 6.5 million reports. The estimated damages exceeded $75 million per hour. Services affected included Vanguard, Robinhood, Canvas (affecting millions of students), Microsoft Teams, Roblox, Fortnite, Hulu, and countless others. A single software bug in one Virginia data center created a cascading failure across AWS's global infrastructure.
October 29, 2025: Microsoft's Azure Front Door Failure
Just nine days after AWS, Microsoft's Azure Front Door experienced a global service disruption caused by an inadvertent configuration change. The 12-hour outage affected Azure, Microsoft 365, Xbox Live, and thousands of customer-facing services including Starbucks, Costco, Capital One, Canvas by Instructure, Alaska Airlines, and Zoom. Downdetector recorded over 16,600 reports for Azure and 9,000 for Microsoft 365, with peak counts exceeding 100,000 users across all Microsoft services.
November 18, 2025: Today's Cloudflare Collapse
Twenty days after Microsoft's failure, Cloudflare experienced its own configuration-driven outage, affecting an estimated 19-20% of the web and costing $5-15 billion per hour according to SupportMy.website. The pattern is undeniable: configuration errors at major infrastructure providers are creating billion-dollar global disruptions with increasing frequency.
What Changed?
Three major infrastructure failures in 30 days. The acceleration is undeniable, and several factors are contributing:
- Increased Complexity: Modern infrastructure involves increasingly complex interdependencies between services, providers, and configurations
- Automation at Scale: Automated systems can propagate errors faster than humans can respond to contain them
- Consolidated Market Power: A handful of companies now control critical internet infrastructure, creating systemic single points of failure
- Configuration Drift: As systems evolve, configuration files grow and edge cases multiply, eventually exceeding design parameters—as we saw with all three outages this month
- Latent Bugs: Today's incident revealed how dormant bugs can lurk in critical systems until triggered by routine changes, creating "time bomb" vulnerabilities that testing doesn't catch
The DDoS Red Herring
Initial reports of an "unusual traffic spike" led to speculation about a distributed denial-of-service (DDoS) attack, particularly given that Cloudflare had blocked a record-setting 11.5 Tbps DDoS attack just two months earlier. However, this highlights an important lesson: not all traffic anomalies indicate attacks. In this case, the "unusual traffic" was the symptom of cascading internal failures, not an external assault. Organizations must be careful not to misdiagnose infrastructure failures as security incidents, as this can lead to incorrect response strategies.
Industry Voices on Systemic Risk
Benjamin Schilz, CEO of Wire, captured the broader implications in his statement following today's outage:
"The recent Cloudflare outage, occurring only a few weeks after the last major cloud disruption, show how brittle our digital reliance has become. Big cloud outages aren't new, similar mass-scale incidents happened in 2017 and 2021, and regional outages occur regularly, and they will certainly happen again.
The problem is systemic: the three main hyper-scalers (AWS, Google Cloud, and Microsoft Azure) provide roughly two-thirds of the underlying infrastructure the digital world runs on. Their APIs connect everything from banking systems and smart homes to e-commerce, meaning the operational error of just one instantly creates a massive 'single point of failure.'
This high-dependency, predominantly on US-based providers with virtually no real non-US alternatives offering comparable scale, forces us to fundamentally rethink dependencies and access risk within our internal tech stacks."
The October 2025 cloud crisis demonstrated this risk empirically. We're no longer talking about theoretical vulnerabilities—we're watching them play out in real-time with billion-dollar consequences.
Understanding Internet Chokepoints: It's Not Just Cloudflare
While this article focuses on today's Cloudflare outage, the fundamental problem extends across the entire CDN and DDoS protection ecosystem. Organizations face similar concentration risks with:
- Akamai: Another major CDN and security provider with massive market share
- Fastly: Experienced its own significant outage in June 2021 that took down major sites
- AWS CloudFront: Amazon's CDN service, subject to the same AWS infrastructure dependencies that failed in October
- Azure CDN/Front Door: Microsoft's offering, which experienced its own failure in November 2024
The reality is that protecting against DDoS attacks and serving content globally at scale requires infrastructure that only a handful of companies possess. As we explored in our coverage of the record-breaking 3.8 Tbps DDoS attack, the threats that these services mitigate are very real and growing more severe. Organizations legitimately need these protective services—but they also need to acknowledge and plan for the risks these dependencies create.
The CDN Paradox
Organizations face a paradox: CDN and DDoS protection services are essential for availability and security, but relying on them creates new availability and security risks. This isn't a problem that can be solved by simply "not using" these services—the threats they protect against are too severe. Instead, organizations must adopt more sophisticated approaches to vendor risk management and disaster recovery planning. As Jake Moore of ESET noted: "Companies are often forced to heavily rely on the likes of Cloudflare, Microsoft and Amazon for hosting their websites and services, as there aren't many other options." This market reality—limited viable alternatives at the scale required for global operations—makes the concentration risk even more acute. Organizations aren't choosing to put all their eggs in one basket out of convenience; they're doing it because there simply aren't enough baskets.
Third-Party Risk Management: From Checkbox to Critical Business Function
The recurring pattern of infrastructure outages—AWS on October 20, Azure on October 29, and now Cloudflare today—transforms vendor and third-party risk management from a compliance checkbox into a critical business function. Three major infrastructure providers failing within 30 days demonstrates that organizations can no longer afford to conduct superficial vendor assessments that focus solely on data security questionnaires.
Key Components of Effective Third-Party Risk Assessment
1. Infrastructure Dependency Mapping
Organizations must develop comprehensive maps of their infrastructure dependencies, including:
- Direct service providers (your CDN, your cloud provider, your security vendors)
- Nested dependencies (services your providers depend on)
- Shared infrastructure (multiple vendors relying on the same underlying services)
- Geographic concentrations (data centers, cable routes, internet exchange points)
2. Single Point of Failure Analysis
For each critical business function, identify:
- Which third-party services are required for that function to operate?
- Are there multiple vendors in the chain that could cause failure?
- What is the blast radius if each vendor experiences an outage?
- Do you have viable alternatives or failover options?
3. Outage Scenario Planning
Traditional disaster recovery planning often focuses on scenarios where your infrastructure fails. Modern planning must account for scenarios where your vendor's infrastructure fails:
- What happens if your CDN provider experiences a 4-hour outage during peak business hours? (We saw this answer today)
- Can you rapidly fail over to an alternative provider?
- Do you have the ability to serve content directly if all CDN providers are unavailable?
- How long can your business operate without access to critical SaaS applications?
4. Vendor Architecture Review
When evaluating vendors, dig deeper than standard security questionnaires:
- What is their architecture for redundancy and failover?
- What are their historical outage patterns and root causes?
- How do they manage configuration changes at scale?
- What are their rollback capabilities if an update goes wrong?
- Do they have circuit breakers to prevent cascading failures?
- What safeguards exist to prevent configuration files from growing beyond design parameters?
Vendor Risk Management Tools and Frameworks
Conducting comprehensive vendor risk assessments requires structured methodologies and, often, specialized tools. Our Vendor Risk Management (VRM) services at CISO Marketplace provide frameworks for evaluating third-party providers across multiple risk dimensions, including infrastructure resilience, configuration management practices, and disaster recovery capabilities. Key frameworks to incorporate:
- NIST Cybersecurity Framework: Supply Chain Risk Management guidance
- ISO 27036: Information security for supplier relationships
- COBIT: Governance and management of enterprise IT, including third-party risks
- Shared Assessments SIG: Standardized information gathering for vendor risk
Building Resilience: Multi-Provider Strategies and Failover Architectures
Today's Cloudflare failure, combined with the AWS and Azure outages in recent months, makes clear that single-vendor strategies are untenable for critical business functions. Organizations must implement multi-layered redundancy:
1. Multi-CDN Architecture
Rather than relying solely on Cloudflare, Akamai, or any single CDN provider, implement a multi-CDN strategy:
- Primary CDN for normal operations
- Secondary CDN that can be activated during primary outages
- DNS-based failover to automatically route traffic to available providers
- Regular testing of failover procedures (not just annual DR tests)
Tradeoffs: Multi-CDN strategies increase complexity and cost. Organizations must balance resilience against operational overhead. For many businesses, a hybrid approach works best: multi-CDN for critical customer-facing services, single-CDN for internal applications.
2. Direct Origin Fallback
Maintain the capability to serve content directly from your origin servers:
- Ensure origin infrastructure can handle at least minimal production load
- Implement rate limiting and basic DDoS protection at the origin
- Document procedures for bypassing CDN in emergency scenarios
- Accept that performance will degrade, but core functionality remains available
3. Multi-Cloud Strategy for Critical Services
Following the AWS and Azure outages, organizations with critical uptime requirements should consider:
- Active-active deployments across multiple cloud providers
- Geographic distribution beyond single-provider availability zones
- Kubernetes and containerization for cloud portability
- Regular failover testing and "chaos engineering" exercises
4. Decentralized Communication Channels
One LinkedIn user commenting on today's outage made an excellent point about communication strategy:
"This is why I will always be a proponent of: 1. An email newsletter. Own your audience—direct access matters. If I had a big launch today and this happened, or had Meta crashed again, I'd be stressed. 2. A multi-platform approach. If your audience can only find you in one place, you don't have an audience: you have a dependency."
This principle extends beyond marketing to business operations:
- Maintain direct communication channels (email) that don't depend on social platforms
- Have multiple contact methods for critical vendors and customers
- Don't rely exclusively on cloud-based collaboration tools—have offline alternatives
- Maintain local copies of critical documentation and contact information
Integrating Vendor Risk into Business Continuity and Disaster Recovery Plans
Traditional Business Continuity Planning (BCP) and Disaster Recovery (DR) often focus on scenarios where the organization's own infrastructure fails. The infrastructure outages of October-November 2025—AWS, Azure, and now Cloudflare, all within 30 days—demonstrate that BCP/DR must explicitly account for vendor failures.
Updated BCP Scenarios to Include
- CDN/Security Provider Outage: Primary protective services unavailable for 4+ hours (as happened today with Cloudflare)
- Cloud Provider Regional Failure: Entire AWS/Azure/GCP region offline
- SaaS Application Extended Downtime: Critical business applications (Salesforce, Microsoft 365, etc.) unavailable
- Payment Processor Failure: Unable to process customer transactions
- Identity Provider Outage: SSO and authentication services unavailable
- Communication Platform Failure: Primary communication tools (Slack, Teams) offline
BCP Documentation Updates
Your BCP documentation should include:
- Current map of all third-party dependencies for each critical business function
- Alternative vendors or services pre-vetted and ready for activation
- Failover procedures with specific step-by-step instructions
- Contact information for vendor emergency support
- Communication templates for notifying customers/stakeholders of vendor-caused outages
- Degraded operation procedures for functioning without specific vendors
Testing and Validation
Vendor-related BCP scenarios should be tested regularly:
- Tabletop Exercises: Quarterly walk-throughs of vendor outage scenarios
- Failover Testing: Semi-annual testing of actual failover to secondary vendors
- Vendor Communication Drills: Verify that vendor emergency contacts work
- Lessons Learned Reviews: After each real vendor outage (like today's), update procedures based on what did/didn't work
Lessons from Today's Cloudflare Outage: What CISOs and Risk Managers Must Do Now
1. Conduct an Immediate Infrastructure Dependency Audit
Don't wait for the next outage. Map your critical infrastructure dependencies this week:
- List all third-party services that can cause customer-facing outages
- Identify which services have no viable alternatives
- Prioritize based on potential business impact
- Develop mitigation strategies for your top 10 dependency risks
2. Update Executive Communication
Ensure your executive leadership and board understand:
- The organization's critical infrastructure dependencies
- The realistic likelihood of vendor outages (we've seen three major ones in the past 30 days—this is not theoretical)
- The business impact of various vendor failure scenarios
- The cost-benefit analysis of redundancy strategies
3. Revise SLAs and Vendor Contracts
Work with procurement and legal to update vendor agreements:
- Define specific uptime requirements and penalties
- Require detailed post-incident reports (Cloudflare promises one on their blog)
- Establish maximum acceptable recovery time objectives (RTO)
- Include provisions for testing vendor disaster recovery capabilities
- Negotiate credits or compensation for outages
4. Implement Enhanced Monitoring
Don't rely solely on vendor status pages (which can themselves be affected by the outage):
- Implement third-party monitoring of critical vendor services
- Set up alerts for vendor service degradation
- Monitor vendor status pages and social media for early warning signs
- Establish escalation procedures triggered by vendor issues
5. Build a Vendor Incident Response Plan
Create a specific playbook for responding to vendor outages:
- Clear decision-making authority (who decides when to failover?)
- Communication protocols (internal and external)
- Technical procedures for activating redundancy
- Post-incident review process
6. Learn from Today's Specific Failures
Today's outage revealed several specific vulnerabilities to address:
- Monitoring Dependencies: DownDetector itself went down because it relies on Cloudflare—ensure your monitoring tools don't depend on the services they're monitoring
- Public Transit Apps: Critical infrastructure like NJ Transit was affected—evaluate which services are truly "critical" and need higher resilience
- Payment Processing: Uber and DoorDash had payment issues—have backup payment processors ready
- AI Service Dependencies: Both ChatGPT and Claude went down—if your business depends on AI services, have fallback procedures
- Status Page Availability: Monitor Cloudflare's status page independently, but also prepare for scenarios where status pages themselves become inaccessible during outages
7. Understand Your Vendor's Incident Response Timeline
Today's incident demonstrated typical patterns in major infrastructure outages:
- Detection to Acknowledgment: ~15 minutes (11:48 UTC detection to 12:03 UTC public acknowledgment)
- Acknowledgment to Root Cause Identification: ~66 minutes (12:03 UTC to 13:09 UTC)
- Fix Implementation to Resolution: ~90 minutes (13:09 UTC to 14:42 UTC)
- Resolution to Full Recovery: Several more hours for residual issues
- Remediation Complications: During recovery, Cloudflare had to temporarily disable WARP access in London (a privacy/security tool that encrypts traffic), demonstrating how fixes can create temporary additional disruptions
Understanding these timelines helps set realistic expectations for business continuity planning. If your RTO (Recovery Time Objective) is less than 3-4 hours, you cannot rely solely on vendor remediation—you need your own failover capabilities.
The Broader Implications: Internet Centralization and Systemic Risk
Today's Cloudflare outage raises questions that extend beyond individual organizational risk management to the structure of the internet itself.
The Consolidation Problem
As one user noted in the aftermath: "For one company to be able to disable 50% of the internet is... bad. When too much of the internet relies on one vendor, a single outage becomes a global choke point." The internet was designed to be decentralized and resilient, with traffic able to route around failures. But the commercial internet of 2025 has evolved toward consolidation:
- Three major cloud providers (AWS, Azure, GCP) host the majority of internet services
- A handful of CDN providers (Cloudflare, Akamai, Fastly) protect and accelerate most major websites
- Critical undersea cables are owned by a small group of companies
- Major internet exchange points create geographic concentrations of risk
Policy and Regulatory Considerations
The repeated infrastructure failures—three major ones in just 30 days—may prompt urgent regulatory responses:
- Requirements for infrastructure providers to maintain higher redundancy standards
- Mandatory incident reporting timelines
- Stress testing requirements similar to financial sector regulations
- Potential designation of major infrastructure providers as "systemically important"
The Case for Decentralization
Some argue that these outages demonstrate the need for more decentralized internet infrastructure:
- Distributed CDN alternatives using edge computing
- Blockchain-based DNS systems
- Peer-to-peer content delivery networks
- Greater investment in open-source infrastructure alternatives
While these alternatives show promise, they currently lack the scale, performance, and DDoS protection capabilities that organizations require. The path forward likely involves hybrid approaches that balance centralized efficiency with decentralized resilience.
Conclusion: Preparing for the Next Inevitable Outage
Today's Cloudflare outage, following AWS (October 20) and Microsoft Azure (October 29), represents a watershed moment for infrastructure risk management. The message is crystal clear: major internet infrastructure outages are not rare black swan events—they are predictable, recurring incidents that organizations must plan for. With three major infrastructure providers experiencing significant outages in just 30 days, the pattern is undeniable and alarming. We're witnessing a systemic fragility in our digital infrastructure that demands immediate attention. October-November 2025 may be remembered as the month that forced a reckoning with cloud concentration risk. Key takeaways for cybersecurity and risk management professionals:
- Vendor outages are inevitable and accelerating. Three in 30 days proves this is the new normal. Plan for them with the same rigor you plan for your own infrastructure failures.
- Single-vendor strategies are high-risk. Critical business functions require multi-provider redundancy.
- Third-party risk management is critical infrastructure. Invest in comprehensive vendor assessment and monitoring capabilities.
- Configuration errors, not cyberattacks, are driving major outages. All three October-November failures were internal configuration issues. Focus vendor assessments on operational resilience and change management processes.
- Business continuity planning must explicitly account for vendor failures. Update your BCP/DR plans to include vendor outage scenarios—test them regularly.
- Testing is essential. Regularly test your ability to fail over to alternative vendors or operate in degraded mode.
- Economic impacts are massive. Today's $60 billion outage, combined with October's AWS and Azure failures, demonstrates the real cost of infrastructure dependencies.
The internet's centralization around a handful of critical infrastructure providers is unlikely to reverse in the near term. These companies provide genuine value in terms of performance, security, and scalability. But organizations that depend on them must do so with eyes wide open to the systemic risks involved. The question isn't whether your critical vendors will experience outages—it's when they will, how severe those outages will be, and whether your organization will be prepared to respond effectively. The past 30 days have given us three wake-up calls. How many more will it take?
Additional Resources
Related Articles on Breached.company
- When the Cloud Falls: Third-Party Dependencies and the New Definition of Critical Infrastructure - In-depth analysis of the October 20, 2025 AWS outage that preceded today's failure
- Microsoft's Azure Front Door Outage: How a Configuration Error Cascaded Into Global Service Disruption - Examining the October 29, 2025 Microsoft infrastructure failure that occurred just nine days after AWS
- Record-Breaking 3.8 Tbps Distributed Denial of Service (DDoS) Attack - Understanding the threats that CDN providers like Cloudflare protect against
Vendor Risk Management Services
- CISO Marketplace Vendor Risk Management Services - Comprehensive frameworks and tools for third-party risk assessment
Frameworks and Standards
- NIST Special Publication 800-161: Cybersecurity Supply Chain Risk Management Practices
- ISO/IEC 27036: Information Security for Supplier Relationships
- COBIT 2019: Governance and Management of Enterprise IT
- Shared Assessments Standardized Information Gathering (SIG) Questionnaire
This article is part of our ongoing coverage of critical infrastructure security and third-party risk management. For incident response consulting, vendor risk assessments, or vCISO services, visit QSai LLC or explore our resources at CISO Marketplace.
Article published November 18, 2025, during the ongoing Cloudflare recovery efforts. Updated as services continue to be restored.