
How AWS, CrowdStrike, and CDK Global outages exposed the fatal flaw in modern enterprise architecture—and what security leaders can actually do about it
Updated: October 20, 2025 - This article covers the ongoing AWS US-EAST-1 outage affecting 100+ major services globally, one of the largest internet disruptions in history. Status pages continue to update as recovery progresses.

The Outage That Should Surprise No One
At 3 AM Eastern Time on October 20, 2025, a DNS resolution failure in Amazon Web Services’ US-EAST-1 region triggered what’s being called one of the largest internet outages in history. Over 1,000 services went dark. Downdetector logged 6.5 million reports. Even Amazon’s own retail site and Alexa devices stopped working.
But the scale wasn’t fully apparent until the status pages started lighting up like a Christmas tree.
The Cascade: How One Region Took Down the Internet
Here’s a partial list of confirmed affected services—and this is just what we know so far:
Financial Services: Vanguard (peak 232 outage reports), Robinhood, Coinbase, PayPal (peak 105 reports), Navy Federal Credit Union, JP Morgan, Square, Venmo
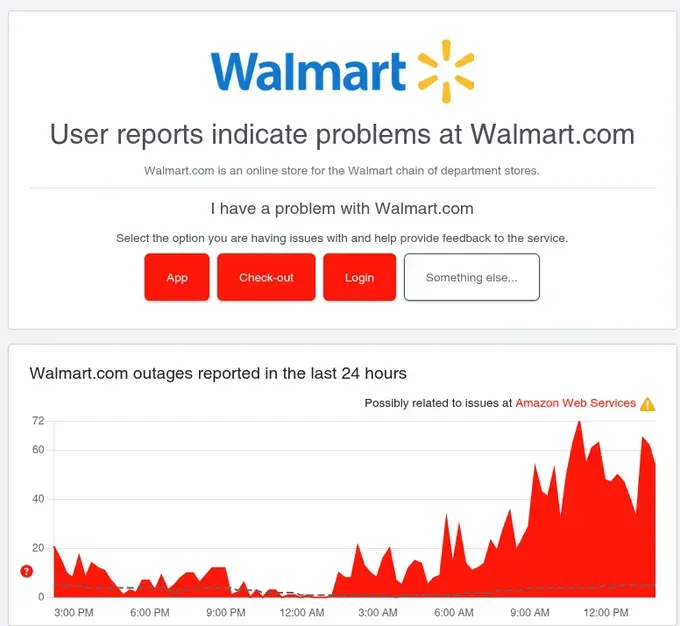
Retail & E-Commerce: Amazon, Walmart (peak 72 reports), eBay, Instacart, GrubHub, McDonald’s app, Starbucks app
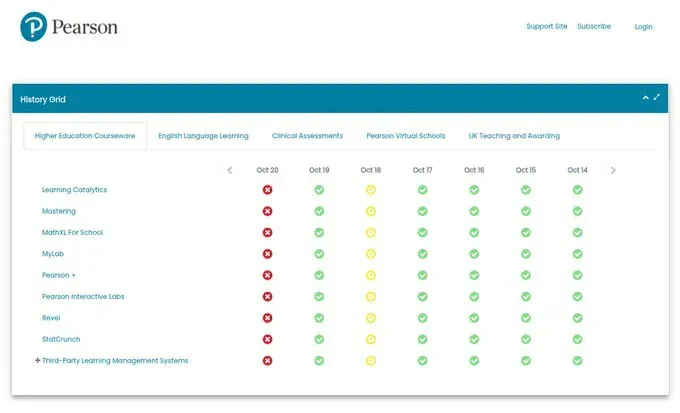
Education: Canvas/Instructure, Pearson, CollegeBoard, MyLab (all education products completely down)
Communication & Collaboration: Slack, Microsoft Teams, Microsoft 365, Zoom, Twilio, Signal, Chime
Entertainment & Gaming: Roblox, Fortnite (Epic Games), PlayStation Network, Xbox, League of Legends, Battlefield (EA), Rainbow Six Siege, Dead By Daylight, VRChat, Steam
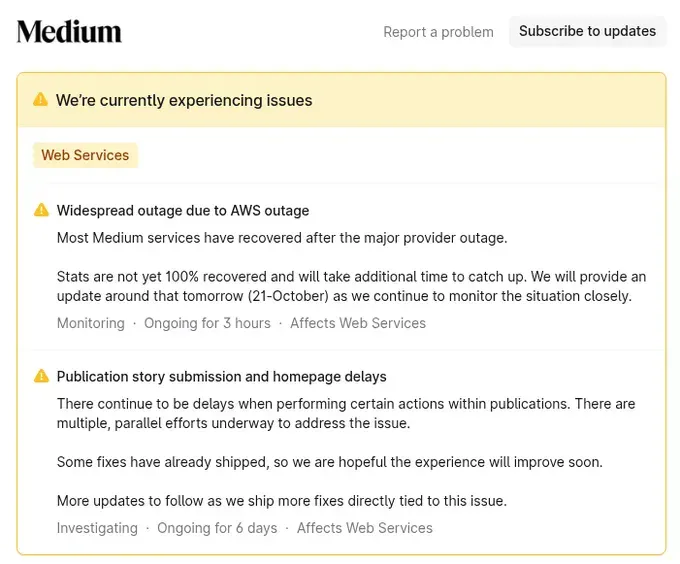
Streaming & Media: Hulu, HBO Max, Disney+ (Disneyland/Disney World apps), Apple Music, Tidal, Roku, Sling, Wall Street Journal, Medium (still experiencing issues hours later)
Travel: Delta Air Lines, United Airlines
SaaS & Productivity: Asana, Trello, Smartsheet, Airtable, Canva, Adobe Creative Cloud
Developer Tools & Infrastructure: GitHub (implicit), Vercel, GoDaddy
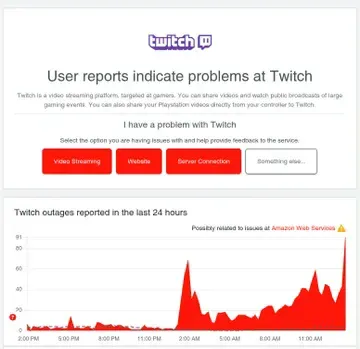
Social Media & Communication: Snapchat, Reddit, Discord, Twitch, TikTok
Security & IoT: Ring doorbells, Blink security cameras
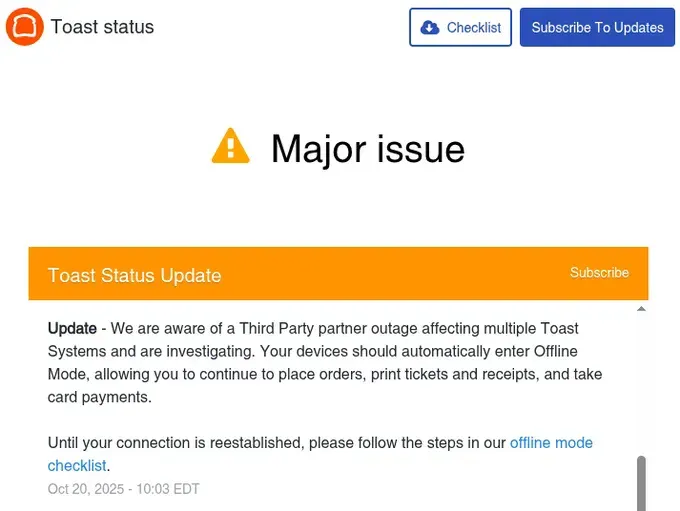
Other Critical Services: ChatGPT, Duolingo, Peloton, MyFitnessPal, Zillow, Xfinity by Comcast, AT&T, T-Mobile, Verizon, Life360, Lyft, Toast POS systems, myKaarma (automotive), Mercado Pago (Latin America payments)
That’s over 100 major services affected. And counting. These are only the confirmed outages—the actual number is likely much higher as not all organizations publicly disclose AWS dependencies.
As one observer noted: “Most of the internet is still down.” That’s not hyperbole when you look at the breadth of impact across every industry sector.
The Global Impact Nobody Predicted
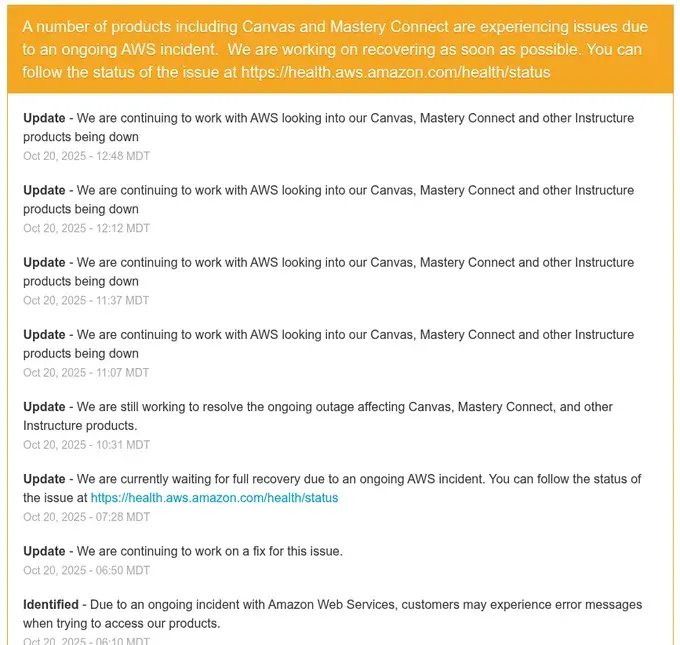
But here’s what should terrify every CISO: services running in Europe crashed despite being thousands of miles from Northern Virginia. Companies like UK’s HMRC (tax authority), Canvas (used by universities globally), and Medium (which stated “Most Medium services have recovered after the major provider outage”) all went down because of a failure in Virginia.
Why? Because AWS’s global account management, Identity and Access Management (IAM), and control APIs—regardless of where your workloads actually run—all route through US-EAST-1. A single region failure cascaded globally, taking down systems that organizations thought were “protected” by geographic distribution.
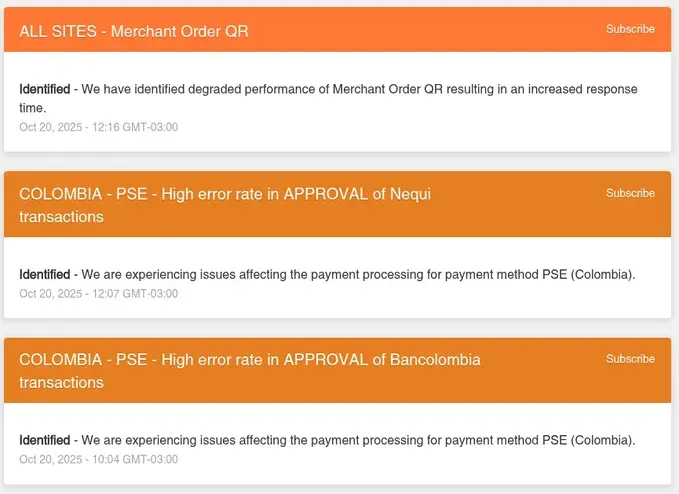
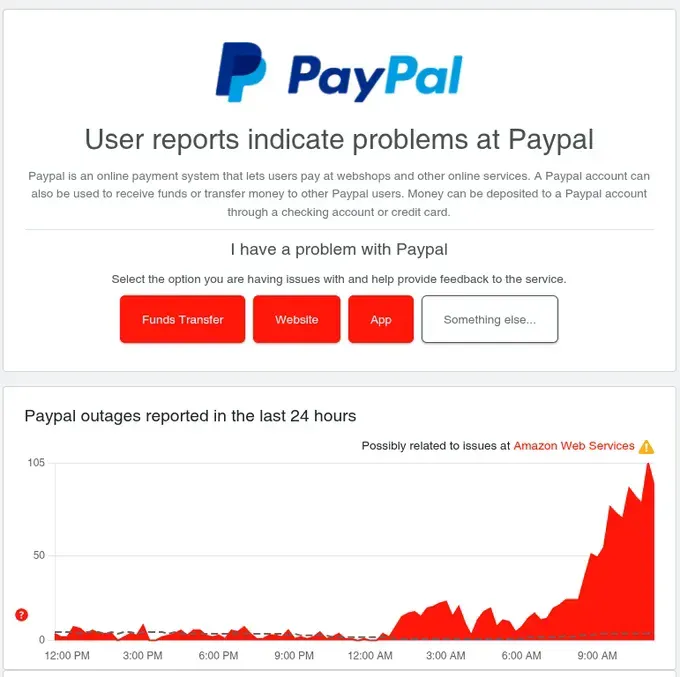
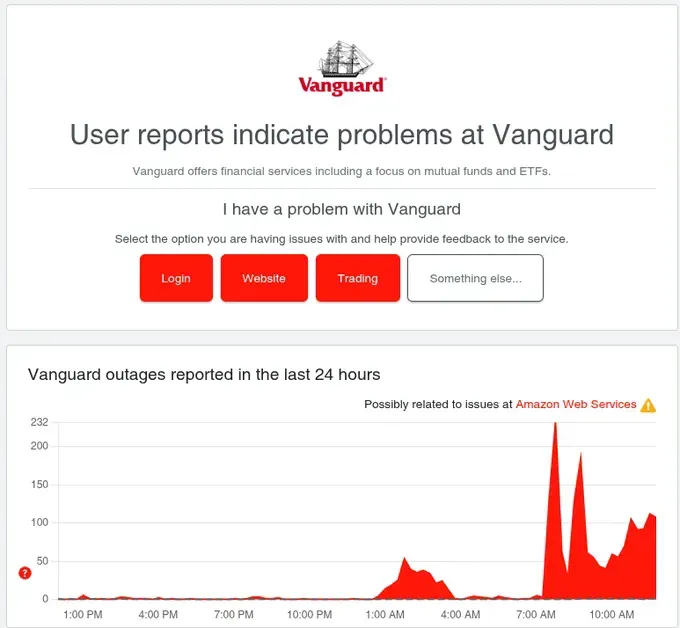
Vanguard’s status page showed the problem clearly: “Possibly related to issues at Amazon Web Services ⚠️” with outage reports spiking from near-zero to 232 in minutes. PayPal showed the same pattern. So did Twitch. And Walmart. And dozens of others.
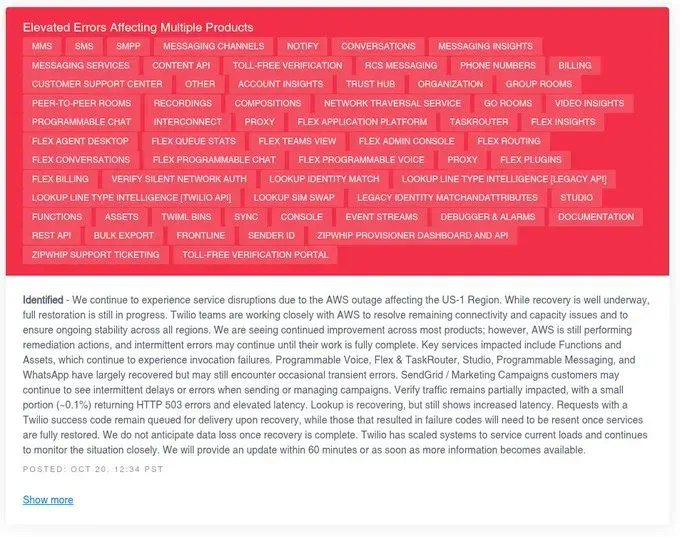
Educational institutions worldwide couldn’t access Canvas. Twilio reported that “elevated errors affecting multiple services” were traced to AWS. Toast POS systems—used by restaurants for orders and payments—went into offline mode, forcing manual operations.
The response from most organizations? “We didn’t know that was possible.”
That’s the problem. And it’s getting worse.
What the Status Pages Revealed
As the outage progressed, something remarkable happened: company after company updated their status pages with nearly identical messages. The language was eerily consistent:
Medium: “Widespread outage due to AWS outage. Most Medium services have recovered after the major provider outage. Stats are not yet 100% recovered and will take additional time to catch up.”
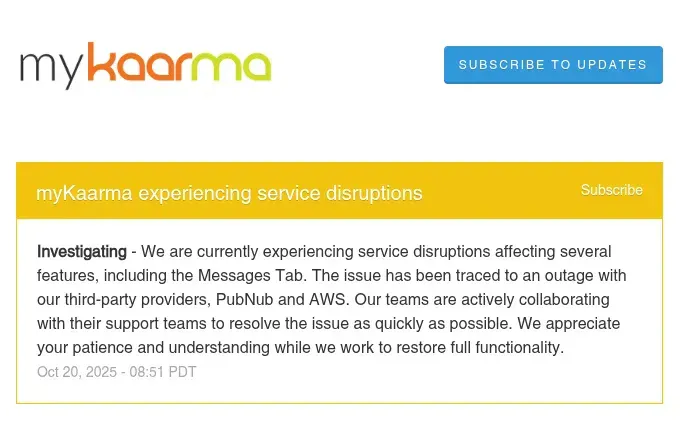
myKaarma (automotive software): “We are currently experiencing service disruptions affecting several features, including the Messages Tab. The issue has been traced to an outage with our third-party providers, PublicHub and AWS.”
Instructure/Canvas (learning management system used by millions of students): “A number of products including Canvas and Mastery Connect are experiencing issues due to an ongoing AWS incident.”
Twilio: “We continue to experience service disruptions due to the AWS outage affecting the US-1 Region… Functions and Assets, which extend across most Twilio products, Programmable Voice, Flex & TaskRouter, Studio, SendGrid/Message Streams, Studio, Programmable Chat, InterConnect, WhatsApp have largely recovered but may still encounter occasional transient errors.”
Toast (restaurant POS systems): “We are aware of a Third Party partner outage affecting multiple Toast Systems and are investigating. Your devices should automatically enter Offline Mode, allowing you to continue to place orders, print tickets and receipts, and take card payments.”
Vanguard (financial services): Outage reports spiked from baseline to 232, with “Possibly related to issues at Amazon Web Services ⚠️”
PayPal: Similar spike in outage reports with AWS correlation flagged
Pearson (educational testing and materials): Multiple products showing red status across their entire grid
Notice the pattern? Every company blamed “a third-party provider” or “AWS” or “an ongoing incident.” None of them could fix the problem themselves. None of them had meaningful redundancy. They could only wait for AWS to restore service.
This isn’t vendor risk. This is systemic infrastructure failure.
And the worst part? Most of these companies probably passed vendor risk assessments that asked “Do you have disaster recovery procedures?” and “Do you have geographic redundancy?” The answers were technically yes. The outcomes were still complete service failure.
The Pattern: When One Vendor Can Destroy an Industry
Today’s AWS outage is just the latest data point in a disturbing trend. Let’s review the recent scorecard of single-vendor catastrophic failures:
October 20, 2025: AWS US-EAST-1 Outage
Scale: One of the largest internet outages in history, affecting over 100 major services Duration: Ongoing for hours, with some services still experiencing issues Root Cause: DNS resolution failure in DynamoDB, cascading to global control plane services Impact: Cross-industry paralysis affecting financial services, education, healthcare, retail, gaming, and government services
The cross-industry impact deserves special attention because it demonstrates how a single vendor has become critical infrastructure across every sector:
Financial Services Paralysis: Vanguard users couldn’t access retirement accounts. Robinhood traders couldn’t execute trades during market hours. Coinbase users couldn’t access crypto holdings. PayPal transactions failed globally. Navy Federal Credit Union members were locked out.
Education System Shutdown: Canvas went down during the school day, affecting millions of students across thousands of institutions globally. Pearson’s entire suite of educational products (Learning Catalytics, Mastery, MyLab, MyLab, Pearson+, Interactive Labs, Revel, StatCrunch, third-party learning management systems) all showed red status. CollegeBoard services were disrupted.
Healthcare Disruption: While not all healthcare impacts are publicly disclosed, the integration between health systems and AWS-dependent services means patient care was affected. Electronic health records, telemedicine platforms, and hospital management systems all depend on the same infrastructure.
Retail and Restaurant Chaos: Walmart’s e-commerce platform experienced significant disruptions. McDonald’s app users couldn’t place orders. Starbucks experienced similar issues. Toast POS systems—used by thousands of restaurants for orders and payments—were forced into offline mode, crippling operations during business hours. Instacart deliveries were delayed or cancelled.
Communication Breakdown: Microsoft Teams stopped working for enterprises. Slack channels went dark. Zoom meetings failed. Twilio-powered communications (used by countless services for SMS, voice, and messaging) experienced elevated errors. Signal messages weren’t delivering.
Entertainment Industry Halt: Roblox’s 70+ million daily users were locked out. Fortnite players couldn’t connect. PlayStation Network and Xbox Live experienced disruptions. Disney’s park apps stopped working, affecting guests trying to access digital tickets and reservations.
 Travel Sector Impact: United and Delta Airlines reported delays and disruptions. Booking systems struggled. Mobile boarding passes became inaccessible.
Travel Sector Impact: United and Delta Airlines reported delays and disruptions. Booking systems struggled. Mobile boarding passes became inaccessible.
This wasn’t just “websites being down.” This was:
- Students unable to submit assignments or take tests
- Patients unable to access medical records
- Traders unable to execute time-sensitive transactions
- Restaurants unable to process payments
- Travelers stranded without boarding passes
- Families unable to access security cameras during emergencies
All because of a DNS resolution failure in one AWS region in Northern Virginia.
CrowdStrike: July 2024
A faulty security software update crashed approximately 8.5 million Windows systems globally in what’s been called the largest IT outage in history. The financial damage? Over $5.4 billion for Fortune 500 companies alone. Healthcare lost $1.94 billion. Banking lost $1.15 billion. Airlines grounded flights. Hospitals canceled surgeries. 911 systems failed.
The root cause? CrowdStrike’s Falcon sensor operates at the Windows kernel level—the core of the operating system. When it crashed, it took everything down with it. Systems entered infinite boot loops, each requiring manual intervention. And because many organizations use BitLocker encryption (ironically, for security), fixing each machine required manually entering 48-digit recovery keys.
CrowdStrike has more than 24,000 customers, including nearly 60% of Fortune 500 companies. One bad update. One vendor. Complete paralysis.
CDK Global: June 2024
A ransomware attack on CDK Global, which provides dealer management software to 15,000 car dealerships across North America, effectively froze the entire auto retail industry for nearly two weeks. Anderson Economic Group estimated direct losses of $944 million.
Dealerships couldn’t track inventory. They couldn’t process financing. They couldn’t run credit checks. They couldn’t generate contracts. They couldn’t even see which car parts needed delivery. Some reverted to pen and paper. Most just shut down.
One parts delivery driver captured the existential dread perfectly: “If hackers can get into a system and take my job away, I feel like it’s probably not the right job to do right now. There’s no security.”
The company reportedly paid around $25 million in Bitcoin to ransomware attackers—a payment that sparked controversy but felt necessary to restore operations for an entire industry.

PowerSchool: December 2024
A breach of PowerSchool’s student information system exposed sensitive data for an estimated 62 million students and 9.5 million teachers across 6,505 school districts. The compromised data included Social Security numbers, medical information, grades, home addresses, and emergency contacts.
The security failure? PowerSchool’s customer support portal lacked basic multi-factor authentication for a system storing millions of children’s most sensitive personal information.
PowerSchool paid ransom to have the data deleted. Months later, threat actors are still using the stolen data to extort individual school districts, proving that paying ransoms guarantees nothing.

The Illusion of Redundancy
Security teams pride themselves on redundancy strategies. Multi-region deployments. Disaster recovery sites. Backup vendors. But these strategies were designed for a different era, and they’re failing in 2025.
Multi-Region Doesn’t Help When the Control Plane is Centralized
Even if you’re running workloads across multiple AWS regions, you’re still dependent on US-EAST-1 for critical services like IAM and global account management. Today’s DNS resolution failure in DynamoDB rippled globally, affecting services that thought they were protected by geographic distribution.
Your “multi-region architecture” is still a single point of failure. You just didn’t know where the single point was.
Multi-Cloud is Expensive and Rarely Implemented
True multi-cloud redundancy—running workloads across AWS, Google Cloud, and Azure—costs significant money. It requires maintaining multiple skill sets, managing different APIs, and essentially building and operating everything twice (or three times).
Most organizations can’t justify the expense when cloud providers constantly tout their reliability. Yet as one industry analyst noted during today’s outage, organizations with true multi-cloud strategies are “feeling smug right now.”
The uncomfortable truth? Multi-cloud is the only real protection against hyperscaler outages. But almost nobody does it.
Kernel-Level Dependencies are Unkillable
CrowdStrike’s Falcon sensor had to operate at the Windows kernel level to provide endpoint protection. That’s the entire value proposition—deep integration to catch threats that surface-level tools miss.
But when kernel-level software crashes, it takes the entire operating system down with it. There’s no “backup” for kernel-level access. There’s no graceful degradation. Even organizations following best practices—keeping one revision behind in production, testing in QA—still got hit because their critical systems relied on this deep integration.
Supply Chain Depth is Invisible
Most organizations have no idea how many layers of third-party dependencies exist in their stack. CDK Global’s customers discovered they couldn’t even register vehicles at the DMV because the DMV integration depended on CDK’s system. PowerSchool’s breach affected not just schools but also the third-party services that integrate with PowerSchool for analytics, communication, and reporting.
The dependency chains go deeper than anyone maps. And when one link breaks, the cascade is unpredictable.
Vendor Risk Management: Why Traditional Approaches Are Theater
Every major enterprise has a vendor risk management program. Vendors complete lengthy questionnaires. They provide SOC 2 reports. They certify compliance with ISO 27001. Security teams check boxes and file reports.
SOC2 Assessment Tool | SOC Compliance ManagementSimplify SOC2 compliance with our comprehensive assessment and management toolSOC Assessment Then a vendor gets ransomware, and 15,000 dealerships shut down for two weeks.
Traditional VRM questionnaires ask:
- “Do you have an incident response plan?” (Yes, filed somewhere)
- “Do you perform annual penetration testing?” (Yes, by our preferred vendor)
- “Do you encrypt data at rest and in transit?” (Yes, using industry standards)
- “Do you have multi-factor authentication?” (Yes, for most systems)
They don’t ask:
- “What happens when your company—who serves 15,000 of our peers—gets hit by ransomware?”
- “Can we actually switch vendors within our contract period, or are we locked in?”
- “Do you have kernel-level access to our systems?”
- “Are there only 2-3 dominant players in this market, meaning ‘diversification’ is impossible?”
- “What percentage of your security budget goes to the team that manages the customer support portal?”
IncidentResponse.Tools: AI-Powered Incident Communication & PlanningGenerate comprehensive cybersecurity incident response documents with AI. Create notifications, press releases, legal briefs, 8-K drafts, and more. Streamline your IR process at IncidentResponse.Tools.
PowerSchool’s customer support portal lacked even basic multi-factor authentication for a system storing millions of children’s Social Security numbers and medical data. Yet PowerSchool almost certainly passed whatever vendor risk assessments its customers performed.
CrowdStrike’s cloud-based testing system had a bug that allowed faulty software to bypass validation checks entirely. Yet CrowdStrike is one of the most trusted names in cybersecurity.
The problem isn’t that vendors are lying on questionnaires. The problem is that questionnaires ask the wrong questions and provide a false sense of security.
The Two Critical Tools Most Organizations Are Missing
Given the cascading nature of modern third-party failures, security leaders need two capabilities that most organizations lack:
1. Comprehensive Vendor Risk Assessment Beyond Questionnaires
Organizations need a systematic approach to vendor risk management that goes beyond static questionnaires and annual reviews. Modern VRM must include:
Continuous monitoring of vendor security posture, not annual snapshots Impact scoring based on actual access levels and data sensitivity Automated evidence collection from vendor trust centers and certifications Real-time alerting when vendor security ratings change Supply chain mapping to understand nested dependencies
Platforms like the Vendor Risk Management tool at CISO Marketplace are designed specifically to address these gaps. Rather than relying solely on self-reported questionnaires, modern VRM tools integrate external security ratings, continuously monitor vendor attack surfaces, and track vendor incidents across your entire supply chain.
The key differentiator: these tools help you understand not just whether a vendor has good security practices, but what happens to your organization when that vendor fails. Impact assessment, not just compliance checking.
For organizations managing dozens or hundreds of vendors, automation becomes essential. The right VRM platform can:
- Automatically tier vendors based on risk exposure (not just spend)
- Trigger reassessments when vendor security ratings degrade
- Map dependencies to understand cascading failure risks
- Provide audit-ready documentation for regulators and boards
Most importantly, modern VRM tools help security leaders answer the question that keeps them up at night: “Which of our vendors could shut us down if they get breached tomorrow?“
2. Incident Response Maturity That Matches the Threat Landscape
Here’s an uncomfortable reality: the question isn’t if a critical vendor will fail, but when. And when they do, your incident response capabilities become the difference between a manageable disruption and a business-ending crisis.
Yet most organizations don’t actually know how mature their incident response capabilities are. They have playbooks that haven’t been updated in years. They have team members who have never actually responded to a real incident. They have communication plans that assume systems will be available to execute those plans.
During the CDK Global ransomware attack, many dealerships discovered their incident response “plan” assumed they’d have access to their dealer management system to… manage the incident. During the CrowdStrike outage, organizations discovered their “backup communication channels” all relied on systems that were currently crashed.
This is where incident response maturity assessment becomes critical. Organizations need to evaluate their capabilities across five key dimensions:
Preparation: Documented procedures, defined roles, testing cadence, and classification criteria Detection: Monitoring capabilities, analysis procedures, threat intelligence integration, and tooling effectiveness Response: Containment procedures, response coverage, external support relationships, and scenario-based playbooks Communication: Stakeholder protocols, status update mechanisms, and documentation processes Recovery: Structured recovery procedures, lessons learned processes, metrics tracking, and continuous improvement
The IR Maturity Assessment tool provides organizations with a free, framework-based evaluation across all five dimensions. Unlike point-in-time audits, maturity assessments measure the operational effectiveness of your security program, not just whether documentation exists.
The tool provides:
- Visual representation through interactive radar charts showing strengths and gaps
- Personalized, actionable recommendations based on your specific maturity level
- Benchmark comparison to understand where you stand relative to peers
- Quarterly tracking to measure improvement over time
Research shows that organizations with mature detection capabilities identify breaches 74 days sooner than those without. When a vendor failure cascades into your environment, those 74 days can be the difference between a minor incident and a catastrophic breach.
More importantly, mature incident response includes vendor-specific playbooks. When CrowdStrike or CDK Global or PowerSchool fails, do you have a documented response process that doesn’t assume you’ll have access to the failed system? Have you identified alternative vendors for critical functions? Do you have pre-approved communication templates for different stakeholder groups?
Most organizations answer “no” to all of these questions. They discover their IR gaps during the actual crisis, which is the worst possible time for that discovery.
What Actually Needs to Change: A 10-Point Framework for 2025
Given the realities of third-party dependencies in 2025, here’s what security leaders and regulators need to implement:
1. Regulatory Classification of Digital Critical Infrastructure
AWS, Microsoft Azure, Google Cloud, CrowdStrike, Okta, Auth0, CDK Global, PowerSchool, and similar companies should be classified as critical infrastructure providers with corresponding oversight. This means:
- Mandatory stress testing and disaster recovery drills
- Incident disclosure timelines measured in hours, not weeks
- Independent security audits by government-approved assessors
- Capital requirements to maintain operational resilience
If a single company’s failure can shut down hospitals, ground flights, and disable 911 systems, that company is critical infrastructure. Period.
2. Liability Frameworks That Reflect Actual Harm
When PowerSchool’s failure to implement multi-factor authentication exposes 62 million children’s Social Security numbers, the penalty should reflect the magnitude of negligence. When CrowdStrike’s testing system bug causes $5.4 billion in losses, shareholders shouldn’t be the only ones bearing the cost.
We need liability frameworks that:
- Hold vendors accountable for preventable failures (no MFA = negligence)
- Create personal liability for executives who cut corners on security
- Require cyber insurance minimums based on customer count and data sensitivity
- Enable class-action lawsuits with statutory damages, not just actual damages
3. Mandatory Resilience Standards for Critical Vendors
Critical infrastructure vendors should be required to demonstrate:
- Multi-region failover capabilities with regular testing
- Canary deployments for updates (not global rollouts)
- Kill switch capabilities for kernel-level software
- Maximum blast radius limits (no single update can affect >10% of customers simultaneously)
CrowdStrike should never be able to push an update to 8.5 million systems simultaneously. AWS should have regional isolation that actually works.
4. Transparency Requirements for Supply Chain Dependencies
Organizations should be required to disclose their critical vendor dependencies in public filings, just like they disclose financial risks. This creates market pressure for diversification and allows downstream customers to understand their nested dependencies.
If you’re a hospital that relies on CDK Global’s partner for medical equipment delivery, you should know that. Currently, you don’t.
5. Vendor Diversity Mandates for Critical Functions
Just as financial institutions are required to diversify their holdings, organizations should be required to maintain vendor diversity for critical functions. No single vendor should represent >40% of your:
- Cloud compute infrastructure
- Endpoint security
- Identity management
- Critical business process software
This is expensive. It’s also the only thing that prevents industry-wide paralysis when a single vendor fails.
6. Real-Time Vendor Risk Monitoring
Annual vendor risk assessments are security theater. Organizations need:
- Continuous monitoring of vendor security posture using external ratings
- Automated alerts when vendor ratings degrade
- Integration between VRM platforms and SOC tools
- Regular attestations from vendors about changes to their risk profile
Modern VRM platforms can provide this. Most organizations haven’t implemented them.
7. Incident Response Maturity as a Board-Level Metric
Boards receive regular reports on financial metrics, customer satisfaction, and employee engagement. They should also receive quarterly reports on incident response maturity, including:
- Maturity scores across all five IR dimensions
- Time to detect and time to respond trends
- Vendor-specific IR playbook coverage
- Tabletop exercise completion rates
- Lessons learned implementation tracking
What gets measured gets managed. IR maturity needs to be measured.
8. Kill Switch Capabilities for Kernel-Level Software
Any software that operates at the kernel level should be required to have:
- Emergency rollback mechanisms that work when systems are crashed
- Remote disable capabilities that don’t require the crashed software to be running
- Phased rollout requirements with automatic halt on error rate thresholds
- Government-held “break glass” credentials for emergency access
If your software can crash 8.5 million computers, there need to be multiple ways to stop the crash.
9. Vendor Breach Insurance Requirements
Critical vendors should be required to carry cyber insurance with minimum coverage based on:
- Number of customers
- Sensitivity of data stored
- Potential business interruption costs
- Historical incident frequency in their sector
CDK Global’s customers suffered $944 million in losses. PowerSchool’s breach affects 62 million people. The insurance requirements should reflect these realities.
10. Security-by-Design Certification for Cloud Providers
Cloud providers should be required to earn and maintain security-by-design certification that includes:
- Verified regional isolation (prove that US-EAST-1 failure can’t impact EU-WEST-1)
- Mandatory chaos engineering (prove you can survive regional failures)
- Customer-configurable blast radius limits
- Transparent incident reporting with root cause analysis for all major outages
If AWS wants to call itself enterprise-ready, it should prove it through independent certification, not marketing claims.
The 1990s Worldview Meets 2025 Reality
In 1990, critical infrastructure meant:
- Physical assets: power plants, water systems, telecommunications switches
- Local failures with local impact
- Redundancy through physical backup generators and multiple suppliers
- An internet designed to be “nuclear-proof” with distributed routing
In 2025:
- A single DNS resolution failure in one AWS region cascades globally
- A single security software update crashes 8.5 million computers simultaneously
- A single ransomware attack freezes a $950 billion industry for two weeks
- As one expert noted: “The irony is that the internet was designed to be a nuclear-proof communication network. It is clearly not that at all.”
The concentration risk is staggering. CrowdStrike alone has more than 24,000 customers, including nearly 60% of Fortune 500 companies. AWS is even more dominant. When these single points of failure collapse, they don’t just disrupt businesses—they shut down hospitals, ground flights, disable 911 systems, and prevent children from going to school.
Modern critical infrastructure isn’t just the power grid and water supply. It’s AWS, Google, Microsoft, Stripe, Cloudflare, GoDaddy, Okta, Twilio, Atlassian, GitHub, Zoom, Salesforce, Snowflake, and Datadog. These companies have themselves become the backbone on which modern businesses, governments, and critical sectors depend.
When one of them goes down, hospitals, banks, logistics networks, and national services are disrupted—often more severely than if a local utility failed.
What Security Leaders Can Do Right Now
While we wait for regulators to catch up with reality, CISOs and security leaders can take immediate action:
Assess Your Current State
Run an incident response maturity assessment. Use tools like IR Maturity Assessment to understand your current capabilities across preparation, detection, response, communication, and recovery. Be honest about gaps. Share results with your board.
Today’s AWS outage revealed critical gaps in incident response maturity for most organizations:
- Detection failures: Many organizations didn’t know they had a problem until customers complained. Their monitoring was focused on their own infrastructure, not their vendors’ status. Organizations with mature IR programs had automated monitoring of AWS Health Dashboard and vendor status pages, receiving alerts within minutes rather than hours.
- Communication chaos: Status page updates became the primary source of truth, but most organizations lacked pre-approved communication templates for “critical vendor down” scenarios. Teams scrambled to figure out what to tell customers, employees, and stakeholders while simultaneously trying to understand scope and impact.
- Response paralysis: Without vendor-specific incident response playbooks, teams didn’t know what to do. Should they wait for AWS? Should they try to failover to another provider? Should they activate business continuity procedures? Most organizations had no documented answer.
- Recovery confusion: As services started coming back online inconsistently, organizations struggled to validate functionality. Which services were actually restored? Which still had degraded performance? Were database writes successful during the outage? Testing and validation procedures were ad-hoc at best.
The organizations that handled today’s outage best had one thing in common: they had invested in incident response maturity before the crisis hit. They had:
- Real-time monitoring of vendor health indicators
- Pre-defined escalation paths for vendor outages
- Communication templates ready to deploy
- Documented decision trees for “wait vs. failover” scenarios
- Testing procedures to validate vendor service restoration
These capabilities don’t emerge during a crisis. They must be built, tested, and refined before you need them. That’s what incident response maturity assessment helps you achieve—understanding where you are today and building a roadmap to where you need to be.
Map your vendor dependencies. Not just who you pay, but who they depend on, and who those vendors depend on. Understand your nested supply chain. Identify single points of failure.
Implement Better VRM Processes
Move beyond static questionnaires. Implement continuous vendor risk monitoring using platforms like CISO Marketplace’s VRM tool that provide real-time security ratings, automated evidence collection, and impact-based risk scoring.
Create vendor tiers based on blast radius, not spend. Your $50,000/year identity provider that every employee authenticates through is higher risk than your $500,000/year consultancy that writes reports.
Build vendor-specific incident response playbooks. What’s your plan when AWS goes down? When CrowdStrike pushes a bad update? When your HR platform gets ransomware? Document these scenarios. Test them annually.
Push for Contractual Protections
Negotiate better breach notification terms. Default 72-hour notification windows are too long. Demand 24-hour notification for any security incident affecting your data.
Require business continuity insurance. Make vendors carry insurance that covers your business interruption costs, not just their own.
Include security degradation triggers. If a vendor’s security rating drops below a threshold, you should have contractual rights to additional audits or even termination without penalty.
Build Real Resilience
Implement multi-cloud for critical workloads. Yes, it’s expensive. Yes, it’s complex. Yes, it’s necessary. Start with your most critical systems.
Maintain offline copies of critical data and processes. When your vendor is down, can you operate in degraded mode? Most organizations can’t because they’ve outsourced too much of their core functionality.
Run vendor failure tabletop exercises. Simulate your top 10 vendors simultaneously failing. What breaks? What’s your recovery time? Who makes decisions? Test these scenarios quarterly.
Advocate for Change
Share your war stories. When vendors fail and cause you real harm, document it. Share it with industry groups. Push for collective action.
Support regulatory initiatives. When regulators propose treating cloud providers as critical infrastructure, support it. When they propose mandatory breach disclosure timelines, support it.
Join industry consortiums. Organizations like FS-ISAC, H-ISAC, and others are working on shared intelligence and collective defense. Participate actively.
The Next Outage is Coming
Today’s AWS outage—one of the largest in internet history—will be resolved. Systems will come back online. AWS will update its Health Dashboard with detailed root cause analysis. Vendors will issue statements about “internal networking issues” and promise to implement additional safeguards. Life will return to normal.

The AWS Health Dashboard told the story in real-time throughout October 20, 2025:
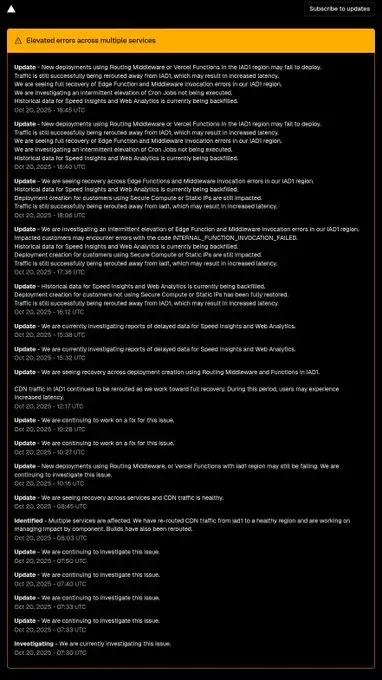
- “New deployments using Routing Middleware or Vend Functions in the IAM region may fail to deploy”
- “Elevated error rates across multiple services”
- “We are seeing recovery across services but Edge Functions and Middleware invocation errors in us-east-1”
- “We are investigating reports of delayed Slack for Speed Insights and Web Analytics”
- “Historical data for Speed Insights and Web Analytics is currently being backfilled”
- “Some instances of Observability are affected; we have restored DNS traffic flow but still is not a healthy region”
- “We are continuing to work on a fix for this issue”
- “We are continuing to investigate this issue”
Each update represented millions of users locked out, thousands of businesses paralyzed, and countless critical services disrupted. And this pattern—incremental updates, extended timelines, cascading failures—will repeat.
Because the fundamental architecture hasn’t changed. We’re still building critical infrastructure on single points of failure. We’re still trusting vendors with kernel-level access to millions of systems. We’re still conducting vendor risk management as box-checking exercises rather than real risk mitigation.
The concentration of power in a handful of technology providers isn’t just a market dynamics problem—it’s a national security problem. It’s a public safety problem. It’s a “students can’t take tests because Canvas is down” problem. It’s a “restaurants can’t process payments because Toast is down” problem. It’s a “traders can’t access markets because Vanguard is down” problem.
CrowdStrike. CDK Global. PowerSchool. AWS (October 2025). These aren’t isolated incidents. They’re symptoms of a systemic problem: we’ve outsourced critical infrastructure to vendors who aren’t held to critical infrastructure standards.
The question isn’t whether the next catastrophic vendor failure will happen. It’s which vendor will fail next, and whether your organization will survive when it does.
The tools exist to assess your incident response maturity. The platforms exist to implement better vendor risk management. The architectural patterns exist to build real resilience.
The question is: will you wait for the next CrowdStrike-scale disaster—or the next AWS outage that dwarfs today’s—to implement them, or will you act now?
Because I promise you—the next outage is already in motion. Someone’s updating code right now. Someone’s misconfiguring a firewall. Someone’s clicking a phishing link in a vendor’s customer support department.
And when that next vendor falls, the only question that matters is: are you ready?
Take Action
Assess Your Incident Response Maturity: Visit ir.breached.company for a free evaluation of your IR capabilities across five critical dimensions. Get personalized recommendations and track your progress quarterly.
Modernize Your Vendor Risk Management: Explore comprehensive VRM tools at CISO Marketplace to move beyond static questionnaires and implement continuous vendor security monitoring.
Share This Article: Forward to your board, your leadership team, and your peers. The conversation about third-party risk needs to happen at every level.
The world has changed since 1990. Our definition of critical infrastructure needs to change with it. And the time to act is now—before the next vendor failure takes your organization offline.


